
Kỷ Luật Chưa Tồn Tại Bốn Năm Trước
Cuối 2022, xây dựng hệ thống với AI đơn giản đến mức lừa dối: bạn gõ một câu hỏi, trầm trồ với câu trả lời. Không có kỷ luật. Không có tooling. Không có hạ tầng. Chỉ là một text box và một model.
Sự đơn giản đó là khởi đầu của thứ gì đó — trong bốn năm tiếp theo — đã phát triển thành một kỹ thuật hoàn chỉnh với patterns riêng, failure modes riêng, và lớp hạ tầng riêng. Từ nghệ thuật viết câu hỏi khéo léo, nó đã trở thành kiến trúc hệ thống. Và câu hỏi trung tâm đã thay đổi ba lần.
2022: “Nói gì với model?” — và prompt engineering là câu trả lời.
2023: “Cho model xem thông tin gì?” — và context engineering xuất hiện.
2025: “Cần xây hệ thống gì?” — và câu trả lời là harness engineering.
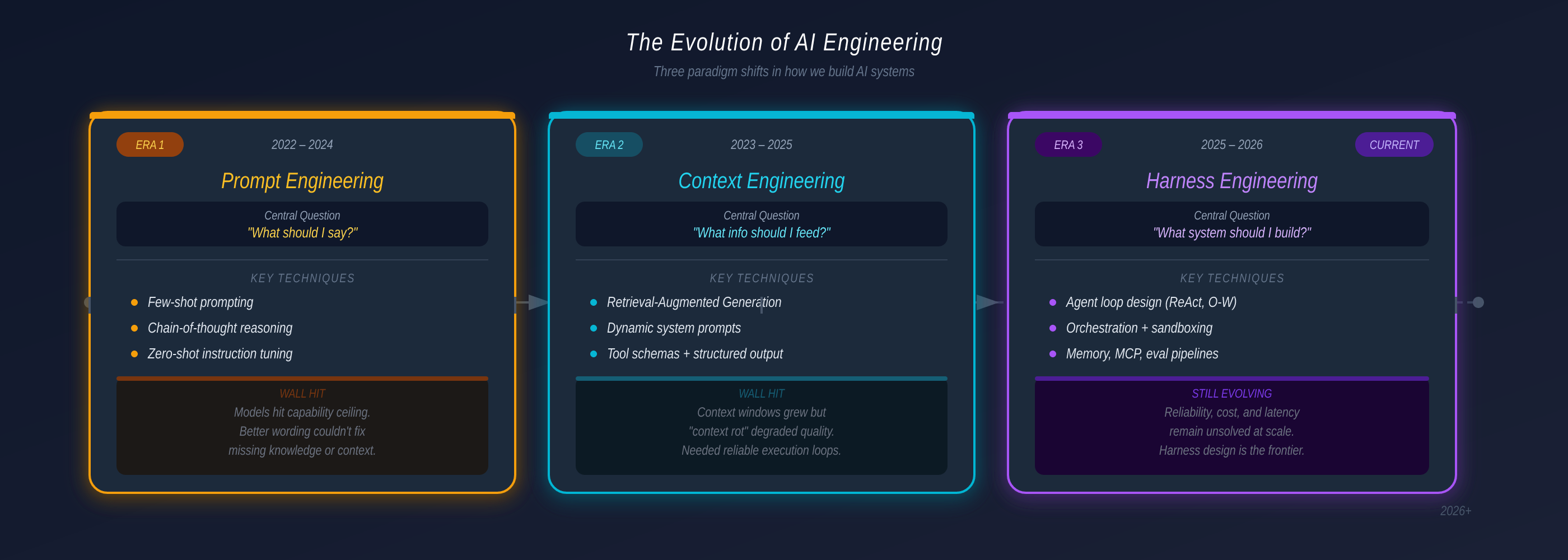
Mỗi bước chuyển xảy ra vì thế hệ trước đụng phải một bức tường cấu trúc không thể vượt qua chỉ bằng kỹ thuật tốt hơn. Bottleneck cứ di chuyển — từ diễn đạt, đến thông tin, đến độ tin cậy. Hiểu quá trình đó là cách nhanh nhất để hiểu tại sao các production agentic systems ngày nay trông như vậy.
Phần 1 — Prompt Engineering: “Nói Gì Với Model?” (2022–2024)
Giả định nền tảng của prompt engineering rất thanh lịch: LLMs được train trên hàng tỷ tokens kiến thức nhân loại, nén vào hàng tỷ parameters. Kiến thức đó đã ở bên trong model rồi. Biến duy nhất còn lại là cách bạn diễn đạt yêu cầu. Viết đúng từ, đúng cấu trúc, và bạn mở khóa được câu trả lời đúng.
Trong hai năm, giả định này hoạt động đáng kể.
The hottest new programming language is English. — Andrej Karpathy, 2023
Một bộ từ vựng kỹ thuật phong phú xuất hiện:
| Kỹ thuật | Cách hoạt động | Tốt nhất cho |
|---|---|---|
| Zero-shot | Hướng dẫn trực tiếp, không ví dụ | Task đơn giản, có tính thực tế |
| Few-shot | 2–5 ví dụ nhúng trong prompt | Output cần format cụ thể (JSON, SQL) |
| Chain-of-Thought | ”Hãy suy nghĩ từng bước” | Multi-step reasoning, toán |
| Role prompting | ”Bạn là senior engineer…” | Hành vi chuyên biệt theo domain |
| Self-consistency | Sample N responses, majority vote | Quyết định quan trọng |
# Toàn bộ "stack" năm 2023 — mọi thứ nằm trong prompt
system_prompt = """
You are a senior backend engineer.
Rules:
- Return JSON only
- Handle all edge cases explicitly
- Use snake_case for identifiers
"""
response = openai.chat(
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": query}
]
)
# Không memory. Không tools. Mỗi call bắt đầu từ đầu.Bức Tường: Knowledge Cutoff
Prompt engineering đụng phải một bức tường cấu trúc không thể vượt qua bằng cách suy luận. LLMs bị đóng băng trong thời gian — kiến thức kết thúc tại điểm cắt training. Chúng không biết team bạn ship gì sprint trước, internal API của bạn làm gì, hay lỗi hệ thống vừa xảy ra 5 phút trước.
Không có cách viết prompt nào có thể fix được điều này. Bottleneck đã dịch chuyển từ diễn đạt sang thông tin. Câu hỏi không còn là “nói gì?” — mà là “model thực sự có thể thấy gì?”
Phần 2 — Context Engineering: “Cho Model Xem Gì?” (2023–2025)
Context engineering bắt đầu từ một nhận thức đơn giản: prompt không phải toàn bộ câu chuyện. Object đầy đủ quyết định hành vi của model là context window — tất cả mọi thứ model đọc trước khi generate response, được tập hợp động mỗi turn.
Building with language models is becoming less about finding the right words, and more about answering: “What configuration of context is most likely to produce the desired behavior?” — Anthropic Engineering, 2025

Trong vòng lặp agentic, context không bao giờ tĩnh. Mỗi turn, thêm thông tin tích lũy:
- Conversation history — các turns trước trong hội thoại
- Retrieved knowledge — tài liệu kéo từ nguồn bên ngoài qua RAG
- Tool schemas — mô tả các actions và APIs có sẵn
- Tool results — output từ các tools agent đã gọi
- Memory files — state được persist từ sessions trước
Prompt không còn là thứ bạn viết một lần. Nó trở thành dynamic assembly được build lại mỗi turn — lớn dần, thay đổi, tích lũy state. Và context windows có giới hạn cứng.
Quản Lý Window Hữu Hạn
Ba chiến lược xuất hiện với đánh đổi cơ bản khác nhau:
| Chiến lược | Cơ chế | Đánh đổi | Dùng khi |
|---|---|---|---|
| Raw context | Giữ nguyên mọi thứ | Fidelity cao nhất, tốn token nhất | Sessions ngắn, chi tiết quan trọng |
| Compaction (reversible) | Thay content bằng references (vd: file path thay vì full file) | Không mất dữ liệu nếu re-readable | Sessions dài với nhiều file edits |
| Summarization (lossy) | LLM viết lại history ngắn hơn | Nén cao, mất dữ liệu vĩnh viễn | Phương án cuối cùng |
Thứ tự ưu tiên nghiêm ngặt: Raw context > Compaction > Summarization. Chỉ dùng lossy compression khi bí — detail đã bị summarize đi là mất mãi mãi.
Context Rot: Nhiều Hơn Không Phải Lúc Nào Cũng Tốt Hơn
Phát hiện quan trọng từ research 2024: context rot. Khi số token trong context window tăng, khả năng model nhớ chính xác thông tin từ context đó giảm. Nhồi nhét window không phải lúc nào cũng đúng. Mục tiêu của context engineering tốt là tìm tập tokens nhỏ nhất có signal cao nhất.
Progressive Disclosure
Pattern hiệu quả nhất cho agents nhiều tools: load tên và mô tả ngắn của tools vào context trước, sau đó hydrate full schema khi cần.
Bước 1 → Agent thấy 50 tên tool + mô tả ngắn
Bước 2 → Agent xác định cần tool "database_query"
Bước 3 → Full schema của "database_query" được load vào context
Bước 4 → Tool được gọi, result vào context, schema có thể evictPattern này — được khởi xướng trong các agentic frameworks — đã được áp dụng trong OpenAI Agents SDK (deferLoading: true), CrewAI (v1.10.2+), và LangGraph. Nếu bạn có hơn ~20 tools và chưa làm điều này, bạn đang burn tokens mỗi lần gọi.
Bức Tường: Độ Tin Cậy
Context engineering làm agents thông minh hơn. Nhưng không làm chúng đáng tin cậy hơn. Biết nhiều hơn, thấy nhiều hơn, không giải quyết được vấn đề hành động đúng, phục hồi sau lỗi, hay duy trì hành vi nhất quán qua sessions. Muốn vậy, bạn cần thứ gì đó hơn một window được quản lý tốt — bạn cần một hệ thống được xây bao quanh model.
Phần 3 — Harness Engineering: “Xây Hệ Thống Gì?” (2025–2026)
Harness engineering là kỷ luật thiết kế toàn bộ hạ tầng bao quanh model và làm cho trí tuệ của nó đáng tin cậy trong production.
Công thức quan trọng, từ LangChain tháng 3/2026:
Agent = Model + Harness
Model cung cấp stateless token prediction. Harness cung cấp mọi thứ biến prediction đó thành thứ hữu ích: memory persist, tools có permission gates, orchestration cho tasks phức tạp, sandboxes để thực thi an toàn, và evaluation loops bắt lỗi trước khi chúng compound.
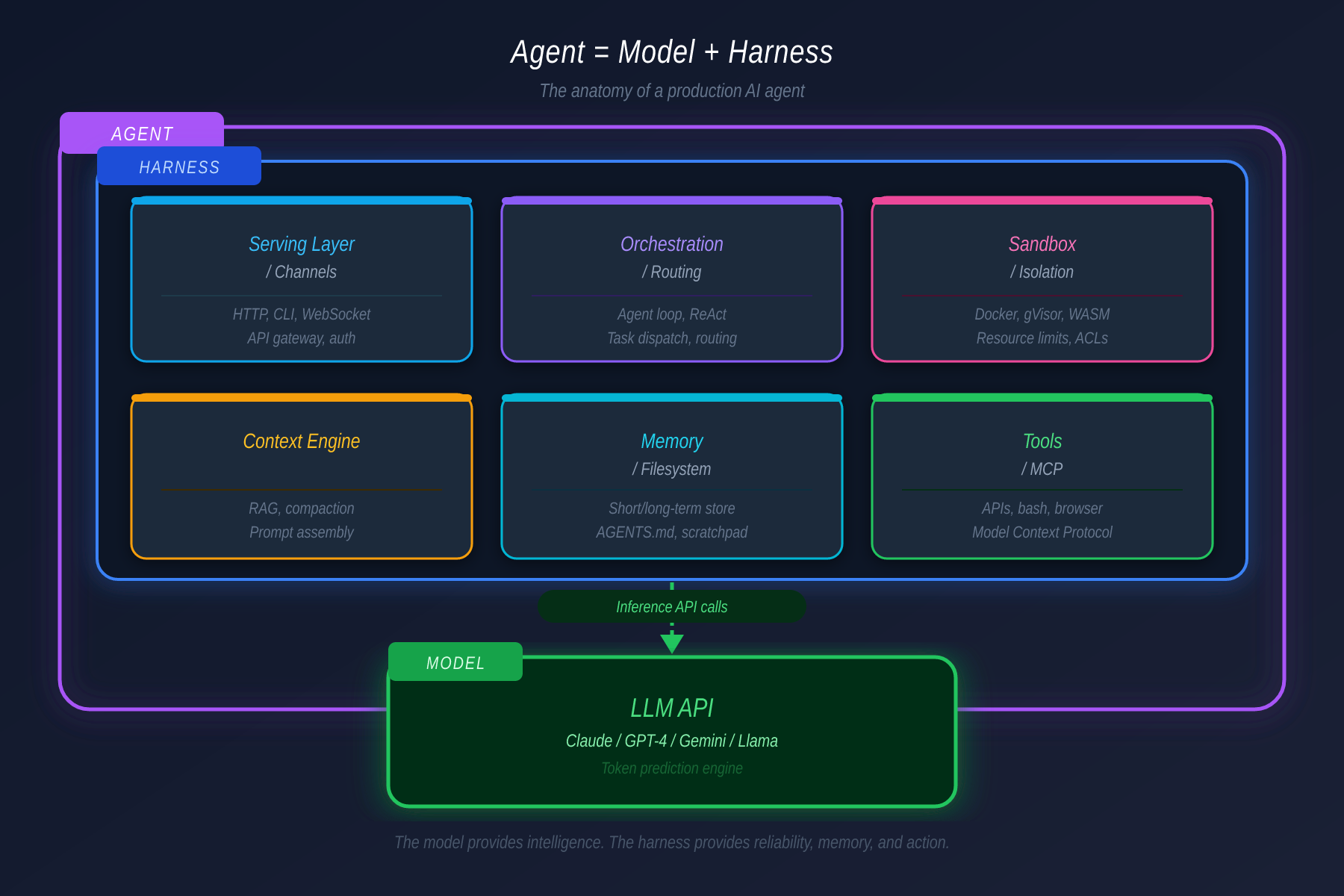
Một harness có sáu lớp riêng biệt:
Layer 1: Serving — Channels
Serving layer là cách agent nhận input và trả output. Insight kiến trúc là Channel abstraction: deploy một agent, kết nối với nhiều bề mặt qua unified gateway. Cùng một brain, cùng memory, accessible từ messaging app, web UI, hay IDE plugin — vì context được chia sẻ phía sau gateway.
| Loại Channel | Context Available | Ví dụ |
|---|---|---|
| IDE / TUI | Files, cursor position, active errors, build output | VS Code plugin, terminal |
| Web app | Session state, user preferences | Custom dashboard |
| Messaging | Text only | Slack, Telegram, WhatsApp |
Model giống hệt trong mọi trường hợp. Gateway normalize inputs trước khi agent thấy chúng.
Layer 2: Orchestration — Routing, Không Phải Entry Point
Orchestration là logic quyết định, cho một task, cách chia nó và ai xử lý phần nào. Nó là router — không phải entry point cho requests (đó là việc của serving layer).
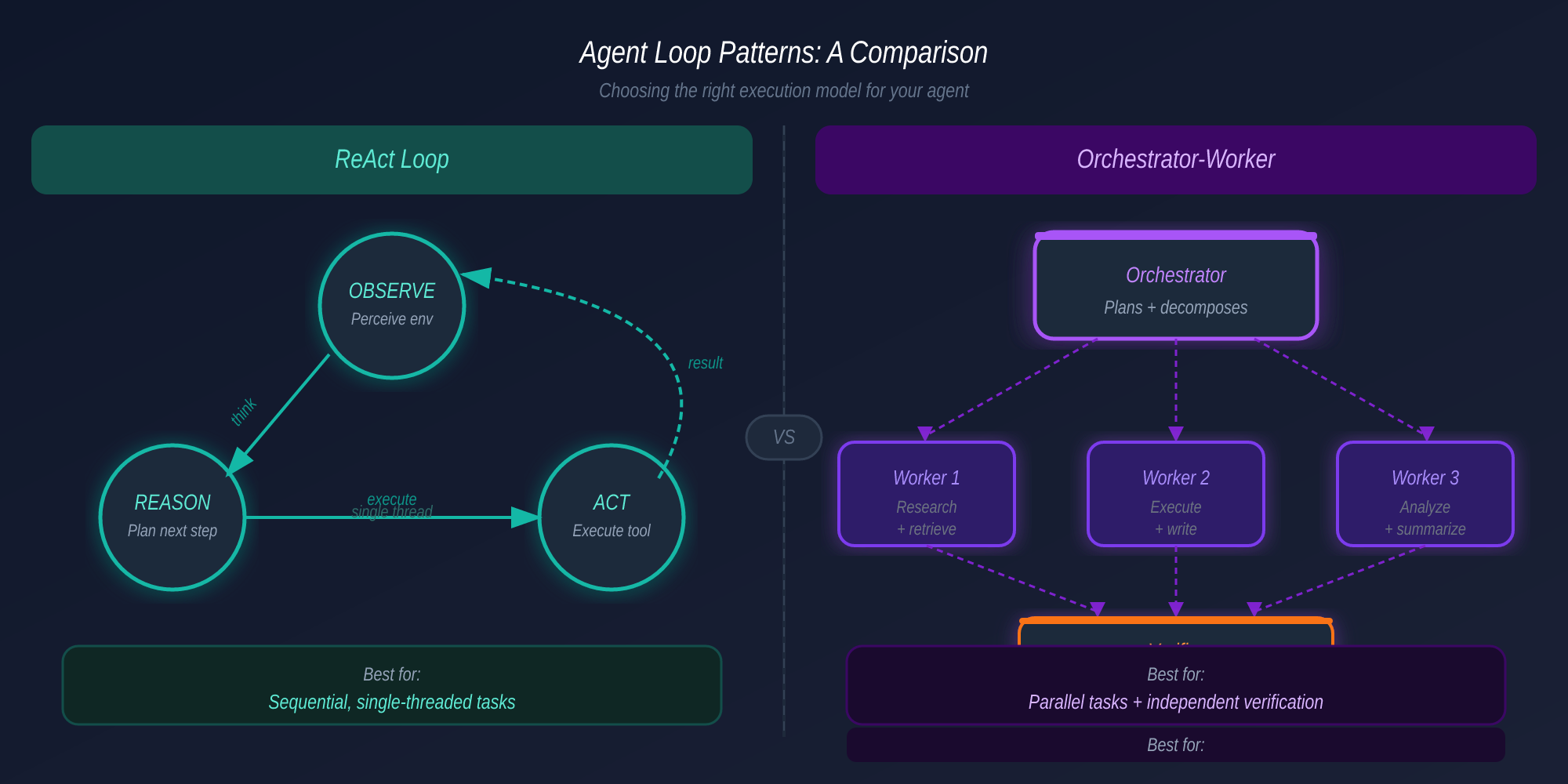
Hai patterns chiếm ưu thế trong production:
Subagent Spawning: Parent agent tạo child agent. Nó viết một prompt mới, gán tool set cụ thể, và copy context window vào child. Child làm việc độc lập với đủ context để hoàn thành task. Đây là cách Agent Teams của Claude Code hoạt động — một session làm team lead, spawn các sub-agents độc lập làm việc song song, phối hợp qua shared task list với dependency tracking.
Multi-agent Coordination: Task được phân tách và context window được chia cho các agents chuyên biệt. Mỗi agent chỉ thấy phần liên quan của mình. Orchestrator thu thập và tổng hợp kết quả. Khác với spawning, context không được replicate — nó được phân vùng.
Sự khác biệt quan trọng: spawning copy context và ủy thác một task. Coordination phân vùng context và phân phối bài toán.
Layer 3: Sandbox — Thực Thi Cô Lập
Agents chạy code. Code đó có thể xóa files, crash systems, hay lộ credentials. Sandboxes đảm bảo failures được containment.
| Mức cô lập | Tốc độ | An toàn | Use Case |
|---|---|---|---|
| Local subprocess | Nhanh nhất | Thấp nhất | Development, thử nghiệm |
| Local Docker container | Trung bình | Trung bình | CI/CD, staging |
| Remote cloud container | Chậm nhất | Cao nhất | Production, untrusted inputs |
Quy tắc credential isolation (học từ production incidents thực tế): credentials không bao giờ được reachable từ sandbox nơi code do agent generate chạy. Một prompt injection thành công trong coupled design là đủ để expose toàn bộ environment. Đây là structural fix, không phải prompt fix.
Layer 4: Context Engine
Ở tầng harness, quản lý context không phải nghệ thuật — nó là engineered component chạy mỗi invocation, quyết định gì vào context window và khi nào. Ba kỹ thuật (compaction, progressive disclosure, tool offloading) không phải practices thủ công — chúng là pipeline stages với điều kiện trigger được định nghĩa.
Claude Code implement năm distinct compaction strategies với profiles latency/fidelity khác nhau: “Snip” nhanh nhưng lossy; “Microcompact” target tool outputs cụ thể. Hai strategies bổ sung vẫn nằm sau feature flags — bằng chứng cho thấy bài toán này thực sự chưa được giải ở quy mô lớn.
Layer 5: Memory — Filesystem, Không Phải Vector Database
| Tier | Là gì | Vòng đời |
|---|---|---|
| Context window | Model đang đọc | Xóa sau mỗi request |
| Session RAM | Conversation history trong process | Mất khi process thoát |
| Filesystem | Markdown files trên disk | Tồn tại qua mọi sessions |
Bản năng khi nghe “agent memory” là với tay lấy vector database và RAG pipeline. Thực tế với hầu hết production systems đơn giản hơn nhiều. Plain Markdown files — human-readable, human-editable, inspectable, và durable — phục vụ như memory layer. File MEMORY.md index trỏ đến topic files, AGENTS.md inject lúc session start, progress file được update sau mỗi work session.
Không embedding pipeline. Không retrieval infrastructure. Memory mà bạn có thể đọc, sửa, và version cùng với code.
Pattern long-running agent: Một initializer agent chạy ở session đầu tiên — viết structured progress file, mô tả state hiện tại, tạo initial commit. Mỗi session tiếp theo đọc file đó trước tiên. Đây là durable knowledge transfer qua sessions với zero infrastructure.
Layer 6: Tools — MCP với Permission Gating
Lý do wrap capabilities như MCP tools thay vì expose raw shell là permission gating. Bash shell cho agent mọi thứ. MCP tool cho agent đúng thứ nó được phép có.
Mọi tool trong một well-designed harness khai báo:
isReadOnly(mặc địnhfalse— giả sử nó write)- Một risk level (low / medium / high)
- Điều kiện khi nào cần explicit human approval
Kết quả là permission system dựa trên default-deny: không gì được phép trừ khi được cấp quyền rõ ràng.
| Tool | Mục đích | Rủi ro |
|---|---|---|
Read / Glob / Grep | Kiểm tra file, tìm kiếm | Thấp — read-only |
Edit | Thay thế text chính xác | Trung bình |
Write | Tạo hoặc ghi đè files | Trung-cao |
Bash | Thực thi scripts tùy ý | Cao |
WebFetch | Fetch URLs bên ngoài | Trung bình |
Agent / Task | Spawn sub-agent | Cao — recursive |
Tính đến giữa 2026, MCP đã vượt 97 triệu lượt tải SDK mỗi tháng và được support native bởi mọi AI vendor lớn — dấu hiệu cho thấy permission-gated tooling đã trở thành infrastructure standard.
Bảy Agentic Design Patterns
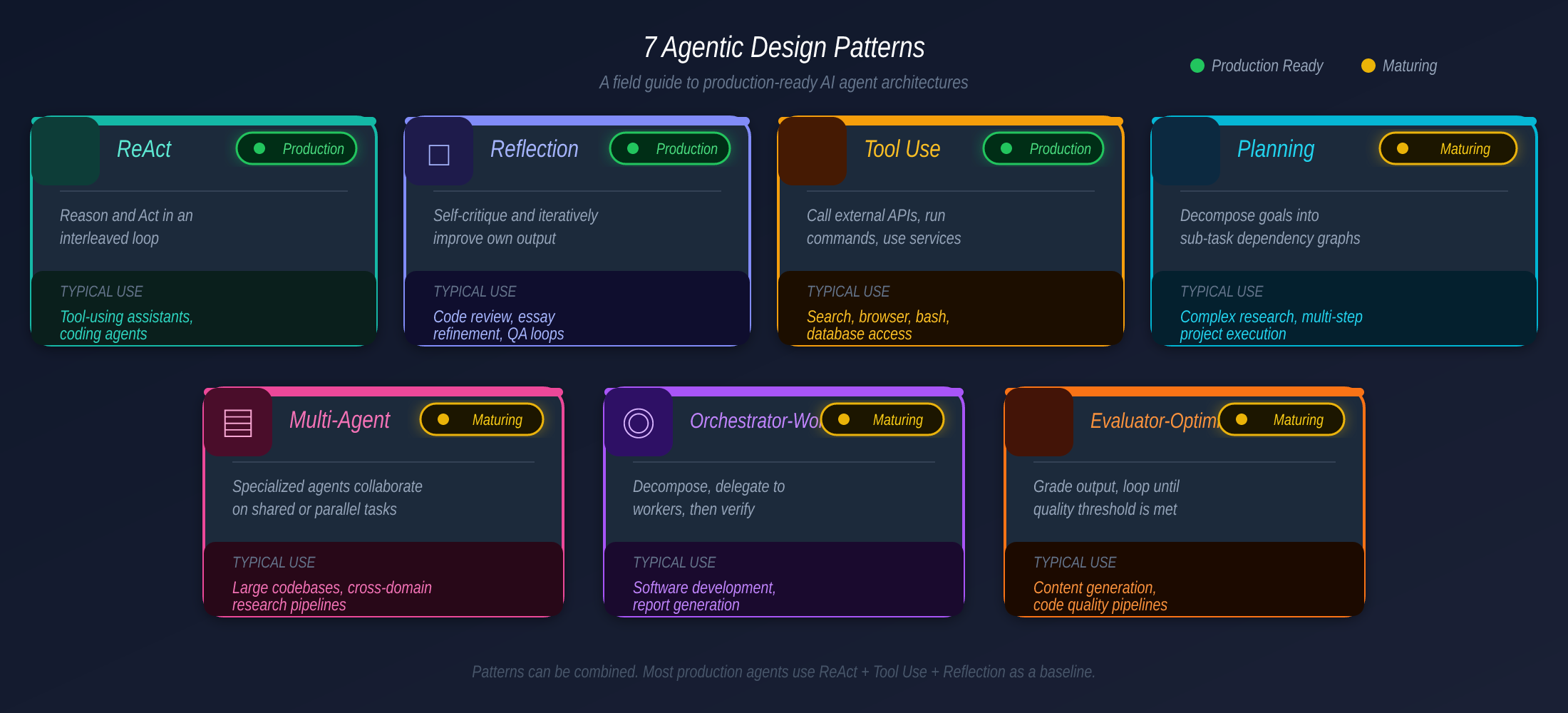
Dựa trên bốn patterns nền tảng của Andrew Ng (2024), ngành đã hội tụ thành bảy patterns composable vào 2026:
| Pattern | Làm gì | Khi nào dùng | Readiness |
|---|---|---|---|
| ReAct | Xen kẽ reasoning + tool calls | Tasks tuần tự, multi-step | 🟢 Battle-tested |
| Reflection | Tự phê bình và lặp lại | Output cần chất lượng cao: code review, writing | 🟢 Mature |
| Tool Use | Gọi external APIs và services | Mọi task cần live data | 🟢 Universal |
| Planning | Phân goal thành dependency graph | Long-horizon goals, workflows phức tạp | 🟡 Maturing |
| Multi-Agent | Agents chuyên biệt phối hợp | Workloads lớn có thể song song hóa | 🟡 Maturing |
| Orchestrator-Worker | Phân tách → ủy thác → xác minh độc lập | Tasks có separable verification | 🟡 Maturing |
| Evaluator-Optimizer | Chấm điểm output theo criteria, loop đến khi đạt | Quality output là bottleneck | 🟡 Emerging |
Các patterns này compose với nhau. Production system hiếm khi chỉ dùng một:
Production Research Agent
Orchestrator-Worker ← phân tách task
Worker 1: ReAct ← research tuần tự
Tool Use ← web search, retrieval
Reflection ← tự kiểm tra findings
Worker 2: ReAct ← phân tích data song song
Tool Use ← database queries
Verifier: Evaluator ← quality gate độc lậpBài Toán Accuracy Cascade
Đây là phép tính thay đổi cách bạn suy nghĩ về per-step reliability:
Nếu mỗi action thành công với xác suất 85%, một workflow 10 actions chỉ thành công khoảng 20% (0.85¹⁰ ≈ 0.197).
Đây là lý do tại sao các patterns Reflection và Evaluator-Optimizer tồn tại — chúng đẩy per-step accuracy từ ~85% lên ~95%, biến 20% end-to-end success rate thành 60%+. Đầu tư vào quality-checking patterns hoàn vốn theo cấp số nhân trong multi-step workflows.
Production Failure Modes
Qua các production deployments thực tế, bốn failure patterns tái diễn:
| Failure | Triệu chứng | Root Cause | Structural Fix |
|---|---|---|---|
| Silent failure | Hệ thống trông bình thường; output sai | Không có independent evaluation layer | Separate verifier agent với scoring criteria |
| Context rot | Agent “quên” chi tiết quan trọng giữa task | Token count vượt ngưỡng recall hữu ích | Compaction strategies, progressive disclosure |
| Permission creep | Agent tích lũy quyền truy cập quá mức | Permission model phẳng, không scoping | MCP default-deny, per-tool risk levels |
| Runaway execution | Tool calls không kiểm soát, chi phí tăng vọt | Không có iteration caps, không budget tracking | Hard caps iterations, token budget per cycle |
Incidents thực tế: Slack AI (tháng 8/2025) — indirect prompt injection cho phép rút dữ liệu từ private channels. Salesforce Agentforce (tháng 9/2025) — malicious inputs dùng để leak CRM data. Đây không phải rủi ro lý thuyết; chúng là production failures được ghi nhận đã định hình security architecture của các harnesses sau này.
Minimum viable observability cho bất kỳ agent nào trong production:
- Trace mọi tool call với full input và output
- Log reasoning steps ở mỗi iteration
- Track token usage mỗi turn và tích lũy
- Alert khi iteration count vượt threshold định nghĩa
- Ghi lại task completion time và kết quả
Kỷ Luật AGENTS.md
Ý tưởng có tác động thực tế cao nhất trong harness engineering không cần hạ tầng mới. Mitchell Hashimoto mô tả nó trong notes công khai về agentic development: một file gọi là AGENTS.md (hoặc CLAUDE.md) nằm ở root của repository.
Mỗi dòng trong file đó đại diện cho một failure thực sự được quan sát và encode thành ràng buộc vĩnh viễn:
# AGENTS.md
## Code Standards
- Không dùng `any` type trong TypeScript — define proper interfaces
- Mọi API responses phải wrapped trong Result<T, E> type
- Database queries phải dùng parameterized statements only
## Architecture
- Không sửa migration files sau initial commit
- Mọi database writes phải qua service layer — không gọi ORM trực tiếp
- API endpoints mới bắt buộc có integration tests trước khi merge
## Agent Behavior
- Chạy full test suite trước khi đánh dấu task hoàn thành
- Không xóa files mà không có xác nhận rõ ràng của user
- Khi design intent không rõ, hỏi — đừng đoán
## Project Context
- Payments service nằm trong monorepo riêng — không import trực tiếp
- Feature flags quản lý qua LaunchDarkly, không phải env vars
- API v1 đã freeze — mọi work mới vào v2File này được inject vào context của agent lúc session start. Nó không phải prompt. Nó không phải documentation. Nó là system constraint — institutional knowledge tích lũy được encode thành durable rules mà agent không thể bypass.
Bắt đầu một file hôm nay. Mỗi lần agent phạm lỗi trong codebase, thêm một rule. Trong vòng một tháng, bạn sẽ có một constraint file cải thiện đáng kể độ tin cậy của agent — với zero infrastructure cost.
Three-Agent Harness Của Anthropic
Anthropic công bố production harness của họ cho long-running development tasks vào tháng 3/2026. Pattern này giải quyết một vấn đề cơ bản của single-agent loops qua tasks dài: models đánh giá quá cao chất lượng output của chính mình, đặc biệt với tasks chủ quan như UI design.
Giải pháp của họ: tách planning, execution, và evaluation thành ba agents riêng biệt.
PLANNER
Đọc requirements
Viết structured feature list + implementation plan
Tạo initial git commit (thiết lập baseline)
|
v
GENERATOR
Đọc plan + progress file
Implement incrementally
Update progress file sau mỗi context reset
(KHÔNG summarize — reset clean với structured state)
|
v
EVALUATOR
Hoàn toàn độc lập — không bao giờ thấy reasoning của generator
Được calibrate với few-shot scoring examples
Chấm điểm output theo explicit criteria
Gửi pass/fail + specific feedback về cho generatorTính độc lập của evaluator là quan trọng. Khi cùng một agent vừa generate vừa evaluate, nó bị bias theo hướng approve những gì nó đã build. Một evaluator riêng, được calibrate với explicit scoring criteria và examples, bắt được failures mà generator sẽ rationalize bỏ qua.
Pattern context reset cũng đáng chú ý: thay vì compress history khi gần đến token limit, generator bắt đầu fresh context mỗi session chỉ dùng structured progress file. Điều này tránh behavior “thận trọng gần context limit” mà compaction đôi khi gây ra.
Framework Landscape: 2026
| Framework | Tốt nhất cho | Language | Multi-Agent | MCP | Learning Curve |
|---|---|---|---|---|---|
| LangGraph | Stateful workflows phức tạp, production | Python | Graph-based | ✓ | Cao (1–2 tuần) |
| CrewAI | Rapid prototyping, role-based collaboration | Python | Role-based DSL | ✓ | Thấp (20 dòng) |
| OpenAI Agents SDK | Production OpenAI-native | Python | Handoff-based | ✓ | Trung bình |
| Anthropic Agent SDK | Claude-native, permission-first | TypeScript | Subagent spawn | ✓ Native | Trung bình |
| Google ADK | Google Cloud / Gemini ecosystem | Python | A2A protocol | ✓ | Trung bình |
| Mastra | Teams TypeScript-first | TypeScript | ✓ | ✓ | Trung bình |
Teams thường bắt đầu với CrewAI để prototyping và migrate sang LangGraph khi cần production-grade state management và conditional routing. Nếu production là mục tiêu ngay từ đầu, bắt đầu với LangGraph hoặc OpenAI Agents SDK tránh được migration cost.
Meta-lesson: Nắm vững một vài composable design patterns quan trọng hơn nhiều so với master bất kỳ framework đơn lẻ nào. Frameworks thay đổi; patterns tồn tại.
Nhìn Toàn Bộ Stack
Ba kỷ luật engineering không thay thế lẫn nhau — chúng xếp thành lớp:
┌──────────────────────────────────────────────────────┐
│ HARNESS ENGINEERING │
│ Tools · Memory · Sandbox · Orchestration · Eval │
│ "Xây hệ thống gì?" │
├──────────────────────────────────────────────────────┤
│ CONTEXT ENGINEERING │
│ RAG · Compaction · Progressive Disclosure │
│ "Cho model xem gì?" │
├──────────────────────────────────────────────────────┤
│ PROMPT ENGINEERING │
│ CoT · Few-shot · Role prompting │
│ "Nói gì với model?" │
├──────────────────────────────────────────────────────┤
│ MODEL │
│ GPT-4o · Claude · Gemini · Llama │
└──────────────────────────────────────────────────────┘Mỗi lớp xây trên lớp bên dưới. Bạn vẫn cần prompts tốt. Bạn vẫn cần context management thông minh. Nhưng leverage đã dịch chuyển lên trên — returns lớn nhất năm 2026 đến từ việc xây harness đúng.
Kỷ luật này đã đi một chặng đường dài từ “gõ câu hỏi, trầm trồ với câu trả lời.” Thứ chúng ta có bây giờ không phải là một chat interface được tinh chỉnh hơn — đó là một lớp distributed systems với failure modes riêng, infrastructure patterns riêng, và engineering discipline riêng. Câu hỏi không còn là “nói gì với AI?” Mà là: “xây gì bao quanh nó?”
References
- Hashimoto, M. (2026). My AI Adoption Journey
- Fowler, M. (2026). Harness Engineering for Coding Agents
- Anthropic Engineering. (2025). Effective Context Engineering for AI Agents
- Anthropic Engineering. (2026). Effective Harnesses for Long-Running Agents
- LangChain. (2026). The Anatomy of an Agent Harness
- Yao, S. et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. Princeton / Google Brain.
- Andrew Ng / DeepLearning.AI. (2024). AI Agentic Design Patterns
- InfoQ. (2026). Anthropic Designs Three-Agent Harness for Long-Running AI Development
- Amazon AWS. (2026). Evaluating AI Agents: Real-World Lessons
- SitePoint. (2026). The Definitive Guide to Agentic Design Patterns in 2026
- SIG. (2026). What Is Harness Engineering?