
The Discipline That Didn’t Exist Four Years Ago
In late 2022, building with AI was deceptively simple: you typed a question, you marveled at the answer. There was no discipline. No tooling. No infrastructure. Just a text box and a model.
That simplicity was the beginning of something that would grow — over the next four years — into a full engineering practice with its own patterns, its own failure modes, and its own infrastructure layer. What started as the art of clever phrasing has become system architecture. The craft has accumulated depth, and the question at its center has shifted three times.
2022: “What should I say?” — and prompt engineering was the answer.
2023: “What information should I feed the model?” — and context engineering emerged.
2025: “What system do I need to build?” — and the answer is harness engineering.
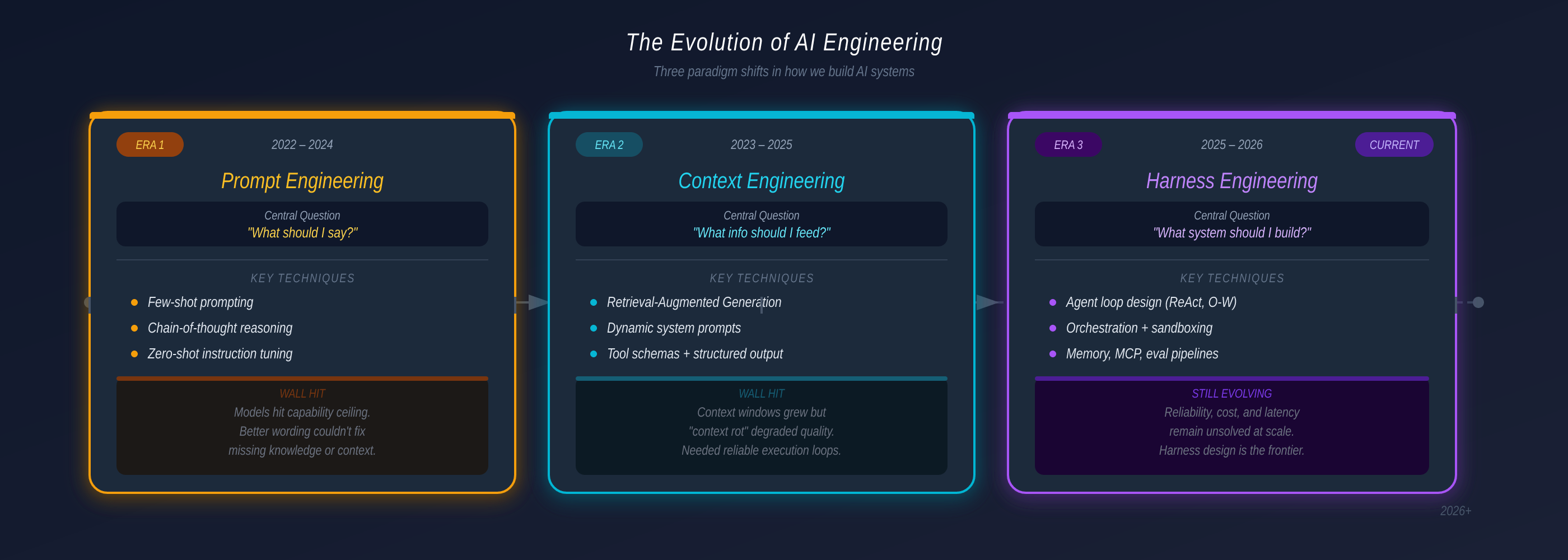
Each shift happened because the previous generation hit a structural wall it could not climb through better technique alone. The bottleneck kept moving — from expression, to information, to reliability. Understanding that progression is the fastest way to understand where the field is today and why production agentic systems look the way they do.
Part 1 — Prompt Engineering: “What Should I Say?” (2022–2024)
The foundational assumption of prompt engineering was elegant: LLMs are trained on billions of tokens of human knowledge, compressed into billions of parameters. That knowledge is already inside the model. The only variable left is how you phrase the request. Write the right words, in the right structure, and you unlock the right answer.
For two years, this assumption held up remarkably well.
The hottest new programming language is English. — Andrej Karpathy, 2023
A rich vocabulary of techniques emerged:
| Technique | How It Works | Best For |
|---|---|---|
| Zero-shot | Direct instruction, no examples | Simple, factual tasks |
| Few-shot | 2–5 examples embedded in prompt | Format-sensitive outputs (JSON, SQL) |
| Chain-of-Thought | ”Think step by step” prefix | Multi-step reasoning, math |
| Role prompting | ”You are a senior engineer…” | Domain-specific behavior |
| Self-consistency | Sample N responses, majority vote | High-stakes decisions |
# The complete "stack" in 2023 — everything lived in the prompt
system_prompt = """
You are a senior backend engineer.
Rules:
- Return JSON only
- Handle all edge cases explicitly
- Use snake_case for identifiers
"""
response = openai.chat(
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": query}
]
)
# No memory. No tools. Every call started fresh.The Wall: Knowledge Cutoff
Prompt engineering hit a structural wall it couldn’t reason its way past. LLMs are frozen in time — their knowledge ends at a training cutoff. They don’t know what your team shipped last sprint, what your internal API does, or what error your system threw five minutes ago.
No amount of prompt refinement can fix this. The bottleneck had shifted from expression to information. The question was no longer “what do I say?” — it was “what can the model actually see?”
Part 2 — Context Engineering: “What Info Should I Feed?” (2023–2025)
Context engineering started from a simple realization: the prompt is not the whole story. The full object that determines model behavior is the context window — everything the model reads before generating a response, assembled dynamically on every turn.
Building with language models is becoming less about finding the right words for your prompts, and more about answering the question: “What configuration of context is most likely to produce the desired behavior?” — Anthropic Engineering, 2025

In an agentic loop, that context is never static. At each turn, more information accumulates:
- Conversation history — previous turns in the dialogue
- Retrieved knowledge — documents pulled from external sources via RAG
- Tool schemas — descriptions of available actions and APIs
- Tool results — outputs from tools the agent has already called
- Memory files — state persisted from earlier sessions
The prompt is no longer something you write once. It becomes a dynamic assembly that gets rebuilt on every single turn — growing, shifting, and accumulating state. And context windows have a hard limit.
Managing the Finite Window
Three strategies emerged, with fundamentally different trade-offs:
| Strategy | Mechanism | Trade-off | Use When |
|---|---|---|---|
| Raw context | Include everything as-is | Highest fidelity, most tokens | Short sessions, critical detail |
| Compaction (reversible) | Replace content with references (e.g., file path instead of full file) | Lossless if re-readable | Long sessions with many edits |
| Summarization (lossy) | LLM rewrites history into shorter form | High compression, permanently lossy | Last resort only |
The hierarchy is strict: Raw context > Compaction > Summarization. Use lossy compression only as a last resort — a detail summarized away is gone forever.
Context Rot: More Isn’t Always Better
A critical finding from 2024 research: context rot. As the token count in a context window grows, the model’s ability to accurately recall information from that context decreases. Packing the window isn’t always the right move. The goal of good context engineering is finding the smallest possible set of high-signal tokens that maximize the probability of the desired output.
Progressive Disclosure
The most effective pattern for tool-heavy agents: load tool names and descriptions into context first, then hydrate the full schema on demand when a specific tool is needed.
Step 1 → Agent sees 50 tool names + short descriptions
Step 2 → Agent identifies it needs "database_query" tool
Step 3 → Full schema for "database_query" loaded into context
Step 4 → Tool called, result enters context, schema can be evictedThis pattern — pioneered in agentic frameworks — has since been adopted across OpenAI Agents SDK (deferLoading: true), CrewAI (v1.10.2+), and LangGraph. If you have more than ~20 tools and aren’t doing this, you’re burning tokens on every call.
The Wall: Reliability
Context engineering made agents smarter. It didn’t make them reliable. Knowing more, seeing more, doesn’t solve the fundamental problem of acting correctly, recovering from failures, or maintaining coherent behavior across sessions. For that, you need something beyond a well-crafted window — you need a system built around the model.
Part 3 — Harness Engineering: “What System Should I Build?” (2025–2026)
Harness engineering is the discipline of designing the full infrastructure that surrounds a model and makes its intelligence reliably useful in production.
The key formulation, from LangChain’s March 2026 anatomy post:
Agent = Model + Harness
The model provides stateless token prediction. The harness provides everything that transforms that prediction into something useful: memory that persists, tools with permission gates, orchestration for complex tasks, sandboxes for safe execution, and evaluation loops that catch failures before they compound.
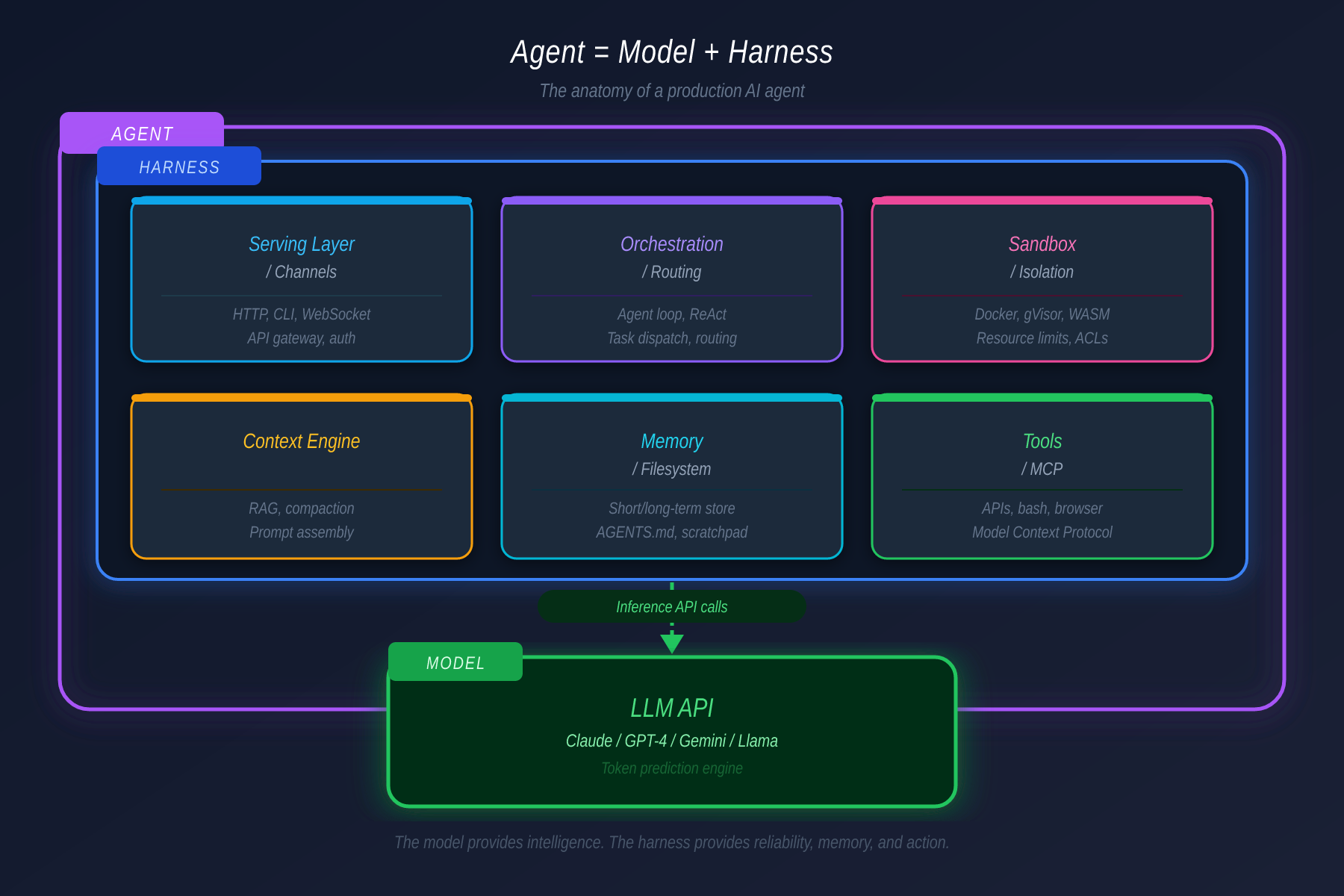
A harness has six distinct layers:
Layer 1: Serving — Channels
The serving layer is how the agent receives input and delivers output. The architectural insight is the Channel abstraction: deploy one agent, connect it to many surfaces through a unified gateway. The same brain, the same memory, accessible from a messaging app, a web UI, or an IDE plugin — because the context is shared behind the gateway.
The richness of context varies significantly by channel:
| Channel Type | Context Available | Examples |
|---|---|---|
| IDE / TUI | Files, cursor position, active errors, build output | VS Code plugin, terminal |
| Web app | Session state, user preferences | Custom dashboard |
| Messaging | Text only | Slack, Telegram, WhatsApp |
The model is identical in all cases. The gateway normalizes inputs before the agent ever sees them.
Layer 2: Orchestration — Routing, Not Entry
Orchestration is the logic that decides, given a task, how to split it and who handles what. It’s a router — not the entry point for requests (that’s the serving layer).
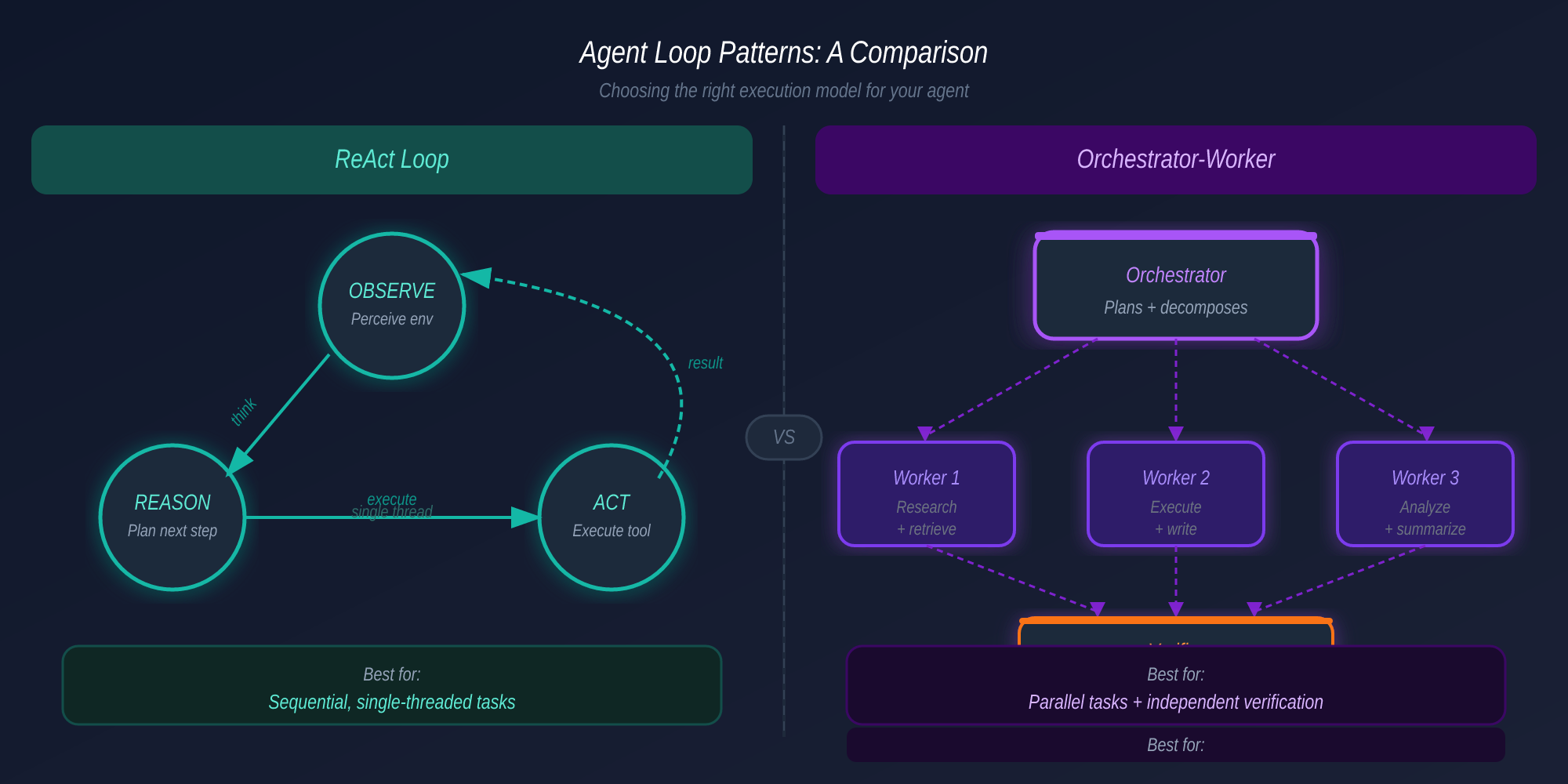
Two patterns dominate production:
Subagent Spawning: The parent agent creates a child agent. It writes a new prompt, assigns a specific tool set, and copies its context window into the child. The child works independently with enough context to complete its task. This pattern is how Claude Code’s Agent Teams feature works internally — one session as team lead, spawning independent sub-agents that work in parallel, coordinated via a shared task list with dependency tracking.
Multi-agent Coordination: The task is decomposed and the context window is divided across specialized agents. Each sees only its relevant slice. The orchestrator collects and aggregates results. Unlike spawning, context is not replicated — it is partitioned.
The key difference: spawning copies context and delegates one task. Coordination partitions context and distributes the problem.
Layer 3: Sandbox — Isolated Execution
Agents run code. That code can delete files, crash systems, or leak credentials. Sandboxes ensure failures stay contained.
| Isolation Level | Speed | Safety | Use Case |
|---|---|---|---|
| Local subprocess | Fastest | Lowest | Development, experimentation |
| Local Docker container | Moderate | Moderate | CI/CD, staging |
| Remote cloud container | Slowest | Highest | Production, untrusted inputs |
The credential isolation rule (learned from real production incidents): credentials must never be reachable from the sandbox where agent-generated code runs. One successful prompt injection in a coupled design is all it takes to expose an entire environment. This is a structural fix, not a prompt fix.
Layer 4: Context Engine
At the harness level, context management is not a craft — it’s an engineered component that runs on every invocation, deciding what enters the context window and when. The three techniques (compaction, progressive disclosure, tool offloading) are not manual practices — they are pipeline stages with defined trigger conditions.
Claude Code implements five distinct compaction strategies with different latency/fidelity profiles: “Snip” is fast but lossy; “Microcompact” targets tool outputs specifically. Two additional strategies remain behind feature flags — evidence of how genuinely unsolved this is at scale.
Layer 5: Memory — The Filesystem, Not a Vector Database
Production agent memory operates across three tiers:
| Tier | What It Is | Lifecycle |
|---|---|---|
| Context window | What the model is literally reading | Cleared after each request |
| Session RAM | Conversation history in-process | Lost when the process exits |
| Filesystem | Markdown files written to disk | Survives all sessions |
The instinct when hearing “agent memory” is to reach for a vector database and a RAG pipeline. The reality for most production systems is far simpler. Plain Markdown files — human-readable, human-editable, inspectable, and durable — serve as the memory layer. A MEMORY.md index pointing to topic files, a CLAUDE.md or AGENTS.md injected at session start, a progress file updated after each work session.
No embedding pipeline. No retrieval infrastructure. Memory that you can read, edit, and version alongside your code.
The long-running agent pattern: An initializer agent runs on the first session — writes a structured progress file, describes the current state, makes an initial commit. Every subsequent session reads that file first. This is durable knowledge transfer across sessions with zero infrastructure.
Layer 6: Tools — MCP with Permission Gating
The reason for wrapping capabilities as MCP tools rather than exposing a raw shell is permission gating. A bash shell gives the agent everything. An MCP tool gives the agent exactly what it is allowed to have.
Every tool in a well-designed harness declares:
isReadOnly(defaults tofalse— assume it writes)- A risk level (low / medium / high)
- Conditions under which it requires explicit human approval
The result is a permission system built on default-deny: nothing is allowed unless explicitly granted. This is what users see as the approval flow in tools like Claude Code — the “auto-approve” vs. “ask me first” toggle is the if-else inside the MCP tool wrapper.
| Tool | Purpose | Risk |
|---|---|---|
Read / Glob / Grep | File inspection, search | Low — read-only |
Edit | Targeted in-place text replacement | Medium |
Write | Create or overwrite files | Medium-high |
Bash | Execute arbitrary scripts | High |
WebFetch | Fetch external URLs | Medium |
Agent / Task | Spawn a sub-agent | High — recursive |
As of mid-2026, MCP has surpassed 97 million monthly SDK downloads and is supported natively by every major AI vendor — a sign that permission-gated tooling has become the infrastructure standard for agentic systems.
The Seven Agentic Design Patterns
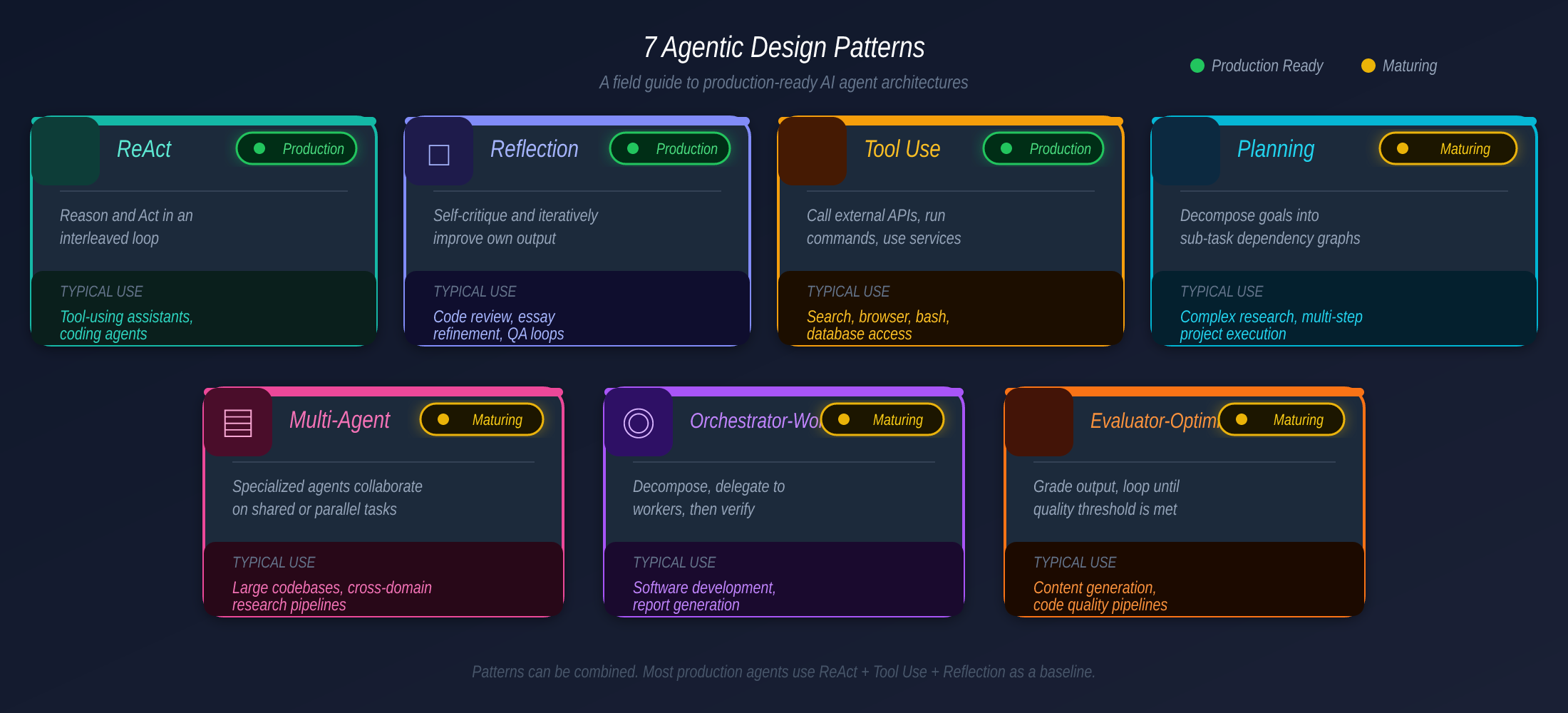
Building on Andrew Ng’s foundational four patterns (2024), the field has converged on seven composable patterns by 2026:
| Pattern | What It Does | When to Use | Readiness |
|---|---|---|---|
| ReAct | Interleave reasoning + tool calls | Sequential, multi-step tasks | 🟢 Battle-tested |
| Reflection | Self-critique and iterate on output | Quality-critical: code review, writing | 🟢 Mature |
| Tool Use | Call external APIs and services | Any task needing live data | 🟢 Universal |
| Planning | Break goal into sub-task dependency graph | Long-horizon goals, complex workflows | 🟡 Maturing |
| Multi-Agent | Specialized agents collaborate | Large parallelizable workloads | 🟡 Maturing |
| Orchestrator-Worker | Decompose → delegate → verify independently | Tasks with separable verification | 🟡 Maturing |
| Evaluator-Optimizer | Score output against criteria, loop until quality met | Output quality is the bottleneck | 🟡 Emerging |
These patterns compose. A production system is rarely just one:
Production Research Agent
Orchestrator-Worker ← task decomposition
Worker 1: ReAct ← sequential research
Tool Use ← web search, retrieval
Reflection ← self-check findings
Worker 2: ReAct ← parallel data analysis
Tool Use ← database queries
Verifier: Evaluator ← independent quality gateThe Accuracy Cascade
Here is the math that changes how you think about per-step reliability:
If each action succeeds with 85% probability, a 10-action workflow succeeds roughly 20% of the time (0.85¹⁰ ≈ 0.197).
This is why Reflection and Evaluator-Optimizer patterns exist — they push per-step accuracy from ~85% to ~95%, which transforms a 20% end-to-end success rate into 60%+. The investment in quality-checking patterns pays off exponentially in multi-step workflows.
Production Failure Modes
Across real production deployments, four failure patterns recur:
| Failure | Symptom | Root Cause | Structural Fix |
|---|---|---|---|
| Silent failure | System looks healthy; outputs are wrong | No independent evaluation layer | Separate verifier agent with scoring criteria |
| Context rot | Agent “forgets” important details mid-task | Token count has exceeded useful recall range | Compaction strategies, progressive disclosure |
| Permission creep | Agent accumulates excessive system access | Flat permission model, no scoping | MCP default-deny, per-tool risk levels |
| Runaway execution | Uncontrolled tool calls, spiraling cost | No iteration caps, no budget tracking | Hard caps on iterations, token budget per cycle |
Real incidents: Slack AI (August 2025) — indirect prompt injection allowing data exfiltration from private channels. Salesforce Agentforce (September 2025) — malicious inputs used to leak CRM data. These are not theoretical risks; they are documented production failures that shaped the security architecture of later harnesses.
Minimum viable observability for any agent in production:
- Trace every tool call with full input and output
- Log reasoning steps at each iteration
- Track token usage per turn and cumulative
- Alert when iteration count exceeds defined threshold
- Record task completion time and success/failure outcome
The AGENTS.md Discipline
The most practically impactful idea in harness engineering requires no new infrastructure. Mitchell Hashimoto described it in his public notes on agentic development: a file called AGENTS.md (or CLAUDE.md) sitting at the root of a repository.
Every line in that file represents a real failure that was observed and encoded as a permanent constraint:
# AGENTS.md
## Code Standards
- Never use `any` type in TypeScript — define proper interfaces
- All API responses must be wrapped in a Result<T, E> type
- Database queries must use parameterized statements only
## Architecture
- Never modify migration files after initial commit
- All database writes go through the service layer — no direct ORM calls
- New API endpoints require corresponding integration tests before merge
## Agent Behavior
- Run the full test suite before marking any task complete
- Never delete files without explicit user confirmation
- When design intent is unclear, ask — do not guess
## Project Context
- The payments service is in a separate monorepo — do not import directly
- Feature flags are managed through LaunchDarkly, not environment variables
- API v1 is frozen — all new work goes to v2This file is injected into the agent’s context at session start. It is not a prompt. It is not documentation. It is a system constraint — accumulated institutional knowledge encoded as durable rules the agent cannot bypass.
Start one today. Every time an agent makes a mistake in your codebase, add a rule. Within a month, you’ll have a constraint file that materially improves agent reliability — with zero infrastructure cost.
The Anthropic Three-Agent Harness
Anthropic published their production harness for long-running development tasks in March 2026. The pattern addresses a fundamental problem with single-agent loops over long tasks: models overestimate the quality of their own output, particularly on subjective tasks like UI design.
Their solution: separate planning, execution, and evaluation into three distinct agents.
PLANNER
Reads requirements
Writes structured feature list + implementation plan
Makes initial git commit (sets baseline)
|
v
GENERATOR
Reads plan + progress file
Implements incrementally
Updates progress file at each context reset
(does NOT summarize — resets cleanly with structured state)
|
v
EVALUATOR
Completely independent — never sees generator's reasoning
Calibrated with few-shot scoring examples
Grades output against explicit criteria
Sends pass/fail + specific feedback back to generatorThe evaluator’s independence is critical. When the same agent that generates also evaluates, it is biased toward approving what it built. A separate evaluator, calibrated with explicit scoring criteria and examples, catches failures the generator would rationalize away.
The context reset pattern is also notable: rather than compressing history when approaching the token limit, the generator starts a fresh context each session using only the structured progress file. This avoids the “caution near the context limit” behavior that compaction sometimes produces.
Framework Landscape: 2026
| Framework | Best For | Language | Multi-Agent | MCP | Learning Curve |
|---|---|---|---|---|---|
| LangGraph | Complex stateful workflows, production | Python | Graph-based | ✓ | High (1–2 weeks) |
| CrewAI | Rapid prototyping, role-based collaboration | Python | Role-based DSL | ✓ | Low (20 lines) |
| OpenAI Agents SDK | OpenAI-native production systems | Python | Handoff-based | ✓ | Moderate |
| Anthropic Agent SDK | Claude-native, permission-first | TypeScript | Subagent spawn | ✓ Native | Moderate |
| Google ADK | Google Cloud / Gemini ecosystem | Python | A2A protocol | ✓ | Moderate |
| Mastra | TypeScript-first teams | TypeScript | ✓ | ✓ | Moderate |
Teams commonly start with CrewAI for prototyping and migrate to LangGraph when they need production-grade state management and conditional routing. If production is the goal from day one, starting with LangGraph or the OpenAI Agents SDK avoids the migration cost.
The meta-lesson: Mastering a handful of composable design patterns matters far more than mastering any single framework. Frameworks change; patterns persist.
The Stack View
The three engineering disciplines don’t replace each other — they layer:
┌──────────────────────────────────────────────────────┐
│ HARNESS ENGINEERING │
│ Tools · Memory · Sandbox · Orchestration · Eval │
│ "What system should I build?" │
├──────────────────────────────────────────────────────┤
│ CONTEXT ENGINEERING │
│ RAG · Compaction · Progressive Disclosure │
│ "What info should I feed?" │
├──────────────────────────────────────────────────────┤
│ PROMPT ENGINEERING │
│ CoT · Few-shot · Role prompting │
│ "What should I say?" │
├──────────────────────────────────────────────────────┤
│ MODEL │
│ GPT-4o · Claude · Gemini · Llama │
└──────────────────────────────────────────────────────┘Each layer builds on the one below it. You still need good prompts. You still need smart context management. But leverage has shifted upward — the largest returns in 2026 come from getting the harness right.
The discipline has traveled a long distance from “type a question, marvel at the answer.” What we have now is not a more refined chat interface — it is a class of distributed systems with its own failure modes, its own infrastructure patterns, and its own engineering discipline. The question is no longer “how do I talk to AI?” It is: “what do I build around it?”
References
- Hashimoto, M. (2026). My AI Adoption Journey
- Fowler, M. (2026). Harness Engineering for Coding Agents
- Anthropic Engineering. (2025). Effective Context Engineering for AI Agents
- Anthropic Engineering. (2026). Effective Harnesses for Long-Running Agents
- LangChain. (2026). The Anatomy of an Agent Harness
- Yao, S. et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. Princeton / Google Brain.
- Andrew Ng / DeepLearning.AI. (2024). AI Agentic Design Patterns
- InfoQ. (2026). Anthropic Designs Three-Agent Harness for Long-Running AI Development
- Amazon AWS. (2026). Evaluating AI Agents: Real-World Lessons from Building Agentic Systems at Amazon
- SitePoint. (2026). The Definitive Guide to Agentic Design Patterns in 2026
- SIG. (2026). What Is Harness Engineering?