
Sắp Đi Phỏng Vấn? Đọc Bài Này Trước
Agentic AI là từ khóa tuyển dụng nóng nhất 2026. Công ty nào cũng muốn có agent riêng. Nếu bạn sắp đi phỏng vấn, khả năng cao sẽ gặp câu hỏi về xây dựng và vận hành AI agent trong production.
Đây không phải bài hype. Đây là ghi chép thực chiến — từ team đã dựng và vận hành AI agent cho khách hàng doanh nghiệp, vấp nhiều, và dần học được cái gì thực sự hoạt động. Tôi viết lại để bạn đỡ mất thời gian như tôi từng mất.
1. “Đã Có ChatGPT, Claude Mạnh Thế Rồi — Sao Còn Phải Tự Dựng Agent?”
Câu này khách hỏi nhiều nhất. Và hỏi đúng. Nhìn bên ngoài thì mấy con chatbot kia làm gì cũng được.
Mạnh thật, thông minh thật. Nhưng có hai vấn đề lớn ở quy mô doanh nghiệp.
Một là chi phí. Gọi API frontier liên tục với volume doanh nghiệp thì hóa đơn không đùa được. Một workflow Bedrock Agent có thể tiêu gấp 4-8 lần token so với bạn ước tính từ prompt người dùng và response cuối — mỗi bước suy nghĩ trung gian, mỗi tool call, mỗi retry đều đốt token.
Hai là đặc thù ngành. Agent general không hiểu business rules của bạn.
Lấy ví dụ thật từ một dự án của tôi: agent security operations cho phòng CCoE (Cloud Center of Excellence) của một công ty lớn. Claude Opus hay GPT-5 giỏi lập trình — không bàn cãi. Nhưng nói về lập kế hoạch penetration test theo chuẩn bảo mật nội bộ, hay viết report đúng format mà CISO muốn đọc? Chúng nó giống đứa intern thông minh ngày đầu đi làm — tài nhưng chưa biết gì về playbook nội bộ.
Khách cần agent làm được:
- Hiểu yêu cầu bảo mật nội bộ của tổ chức
- Học từ các cuộc tấn công trong quá khứ để dựng test plan tương lai
- Tạo report đúng format, đúng insight mà leadership muốn — không phải summary chung chung
Thêm một ràng buộc nữa, quan trọng với mấy tổ chức lớn: chủ quyền dữ liệu. Họ cần mọi thứ chạy trên hạ tầng đảm bảo data không chảy ngược ra ngoài để bị train ở chỗ khác. Dữ liệu bảo mật nội bộ rò ra là to chuyện. Giải pháp: AWS Bedrock chạy Claude Sonnet 4.5 — cân bằng giữa chi phí và chất lượng, data nằm yên trong account của họ.

2. “Thế Hallucination Thì Sao?”
Nghe thì vô lý. LLM nổi tiếng hay bịa, thì kiểm soát chất lượng output kiểu gì?
Bài báo ICLR 2026 “The Reasoning Trap” còn làm tệ hơn — training model reasoning mạnh hơn qua reinforcement learning lại tăng tỉ lệ tool-hallucination. Suy luận giỏi hơn không có nghĩa grounding tốt hơn.
Nhưng thực tế khi làm agent, phần lớn hallucination xảy ra ở đúng hai tình huống:
- Data input không đủ — agent không có đủ thông tin để trả lời, nên tự điền bằng fiction nghe hợp lý
- Overload context window — nhồi nhét quá nhiều vào cửa sổ ngữ cảnh, model loạn
Nếu bạn có cơ chế feed data cho agent đúng cách, hoàn toàn control được chất lượng. Giải pháp nằm ở bộ ba tool-database-RAG: cung cấp cho LLM bộ tool kèm hướng dẫn rõ ràng khi nào dùng cái nào. Agent đi đúng đường thay vì tự bịa.
Quy tắc sống còn: Agent được phép suy luận về cách làm. Nhưng dữ kiện — mọi ID, mọi con số, mọi data point — phải lôi từ database ra. Đừng để agent tự nghĩ ra transaction ID. Nó sẽ trông y như thật, mà sai bét.
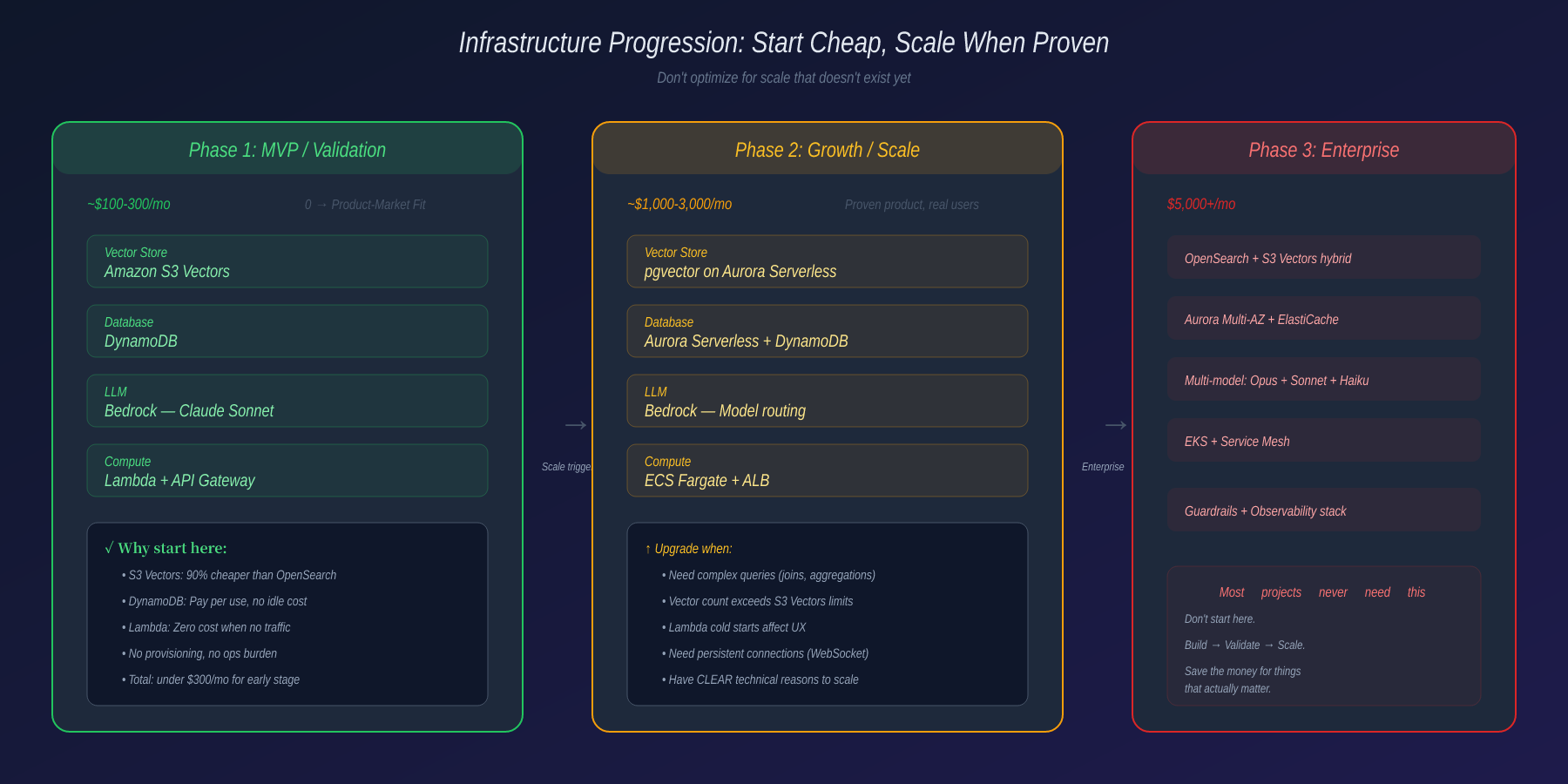
3. Thiết Kế Infra: Start Small Hoặc Đốt Tiền
Trước khi nói chuyện chi phí, phải nói rõ điều mà nhiều bạn mới vào hay tưởng nhầm.
Dựng AI agent không phải chỉ gọi vài cái API LLM rồi xong. Cơ bản nó vẫn là code, y như làm phần mềm bình thường. Thậm chí code nhiều hơn (khóc). Bạn vẫn cần:
- Backend xử lý logic
- Frontend cho người dùng
- Database lưu trữ
- Và bây giờ gánh thêm bill LLM call hàng tháng
Nền tảng kỹ thuật cũ không mất đi đâu. Agentic chỉ chồng thêm một lớp lên trên. Ai tưởng học mỗi AI rồi nhảy vào làm agentic là được thì dễ vỡ mộng. Nói thật, phần AI nhiều khi là phần nhẹ nhất — mệt là mệt ở chỗ ráp nó vào hệ thống chạy được mà không đốt tiền.
Cái Hố Đốt Tiền Hạ Tầng
Đây là chỗ nhiều team đốt tiền oan nhất, ngay từ ngày đầu.
Khi dựng RAG và vector storage cho agent trên AWS, đừng nhảy ngay vào pgvector hay OpenSearch. Đắt, vận hành nặng, và thường over-engineer cho giai đoạn chưa biết sản phẩm sống được không.
Dùng Amazon S3 Vectors. Ra mắt cuối 2025, lưu và query vector ngay trong S3 — rẻ hơn tới 90% so với OpenSearch Serverless, không cần provision hạ tầng, tích hợp sẵn Bedrock Knowledge Bases. Giai đoạn đầu vài chục triệu vector, dư sức gánh. S3 Vectors còn giảm chi phí inference LLM hơn 92% qua tool selection thông minh hơn.
Phần metadata và chat history, thử DynamoDB trước khi dùng RDS. Serverless, trả tiền theo lượng dùng, giai đoạn đầu chưa cần join phức tạp. Cost tối ưu tới mức bất ngờ.
Quy tắc của tôi: Lên prod thật, scale lớn thật, có lý do kỹ thuật rõ ràng rồi hãy đổi sang đồ nặng. Đừng tối ưu cho cái scale chưa tồn tại.
4. Quản Lý Cost: Cái Bẫy Bill Bedrock
Bedrock model mặc định không tag được theo dự án. Một account AWS chạy nhiều project dùng chung model, hóa đơn chỉ hiện cost theo model, không theo project. Sếp nhìn vào chỉ thấy “Claude Sonnet: $X,000” mà không biết dự án nào ngốn tiền.
Giải Pháp: Application Inference Profile
Mỗi dự án tạo một inference profile riêng, gắn cost allocation tag, gọi model qua ARN của profile thay vì model ID trực tiếp. Vào Cost Explorer filter theo tag — ra ngay bill từng dự án.
Hay ở chỗ: dự án đổi model (Sonnet 4.5 → Opus), billing vẫn track theo dự án, không bị reset.
Các Đòn Bẩy Cost Thực Sự Hiệu Quả
| Chiến lược | Tiết kiệm | Khi nào dùng |
|---|---|---|
| S3 Vectors thay OpenSearch | ~90% vector storage | Build mới, < tỷ vectors |
| Prompt caching (1hr TTL) | ~90% cache reads | Hội thoại có trạng thái |
| Model routing (rẻ → frontier) | 40-60% blended cost | Workload đa dạng độ khó |
| Batch inference | 50% per token | Report đêm, phân loại hàng loạt |
| Context compression | Tùy | RAG payload lớn |
5. Kiến Trúc Agent: Chat Mới Là Chỗ Dễ Sảy Chân
99% agent có chức năng chat. Mà chat lại là chỗ nhiều team làm hỏng nhất. Nghe lạ — chat thì có gì khó?
Agent trong lĩnh vực nào phải nói chuyện như nhân viên thật trong lĩnh vực đó. Agent y tế nói như bác sĩ — hỏi đúng triệu chứng, đúng thuật ngữ. Agent security nói như DevSecOps — hiểu ngữ cảnh tấn công, quy trình kiểm thử. Luồng hội thoại mỗi domain khác nhau hoàn toàn. Không thể copy-paste chat từ dự án này sang dự án khác.
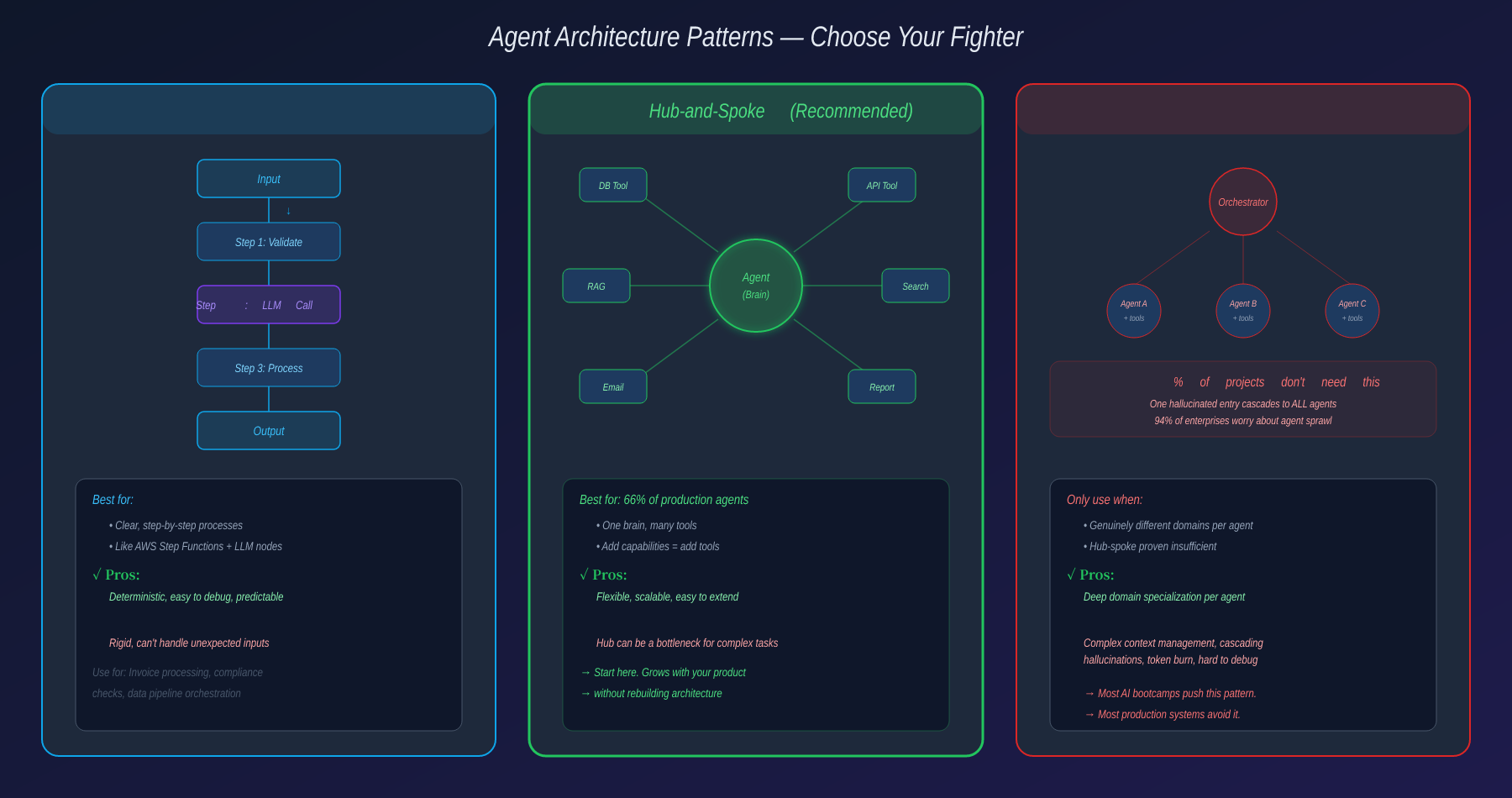
Ba Pattern Kiến Trúc
Phải chọn design pattern ngay từ đầu:
Workflow — Code pipeline (như Step Functions), một số node gọi LLM xử lý phần cần suy luận. Deterministic, dễ debug, hợp quy trình rõ ràng từng bước.
Hub-and-Spoke — Một agent chính, xung quanh là tool vệ tinh. Agent nhìn yêu cầu, loop gọi tool xử lý và trả lời. Một não, nhiều tay chân. 66.4% hệ thống agentic AI production dùng pattern này năm 2026.
Multi-Agent — Một hoặc nhiều orchestrator điều phối, bên dưới là agent con chuyên biệt, mỗi con có tool set riêng.
Cái Bẫy Multi-Agent
Trên mạng và mấy con AI khi được hỏi hay suggest multi-agent. Tôi đọc mà vừa khóc vừa cười.
Vì 99% dự án không cần hơn một agent.
Không phải multi-agent dở. Vấn đề là nó phức tạp. Để multi-agent chạy tốt, bạn phải kiểm soát context và instruction cực kỳ cẩn thận. Thiếu một chút — agent không đủ thông tin. Thừa một chút — đốt token vô ích, bill tính từng token. Nhà nghiên cứu Princeton cảnh báo trong multi-agent chia sẻ memory, một entry hallucinate duy nhất có thể cascade tới mọi agent downstream.
Khảo sát OutSystems 2026 với gần 1.900 IT leaders: 96% doanh nghiệp chạy AI agent — nhưng 94% lo ngại agent sprawl tăng complexity, technical debt, và security risk. Chỉ 12% có nền tảng quản lý tập trung.
Hub-and-spoke thường là đáp án đúng. Yêu cầu có phức tạp tới đâu, agent cứ loop gọi tool. Muốn thêm chức năng? Code thêm tool, update catalog, xong. Kiến trúc lớn lên theo sản phẩm mà không phải đập đi xây lại.
6. Agent Phải Biết Tự Lập Kế Hoạch — Nhưng Dữ Kiện Từ Database
Với yêu cầu phức tạp, agent cần khả năng planning. User bảo làm A, rồi B, rồi C — agent phải tự dựng kế hoạch, biết cái nào trước cái nào sau, cái nào phụ thuộc cái nào.
Nhưng nhớ quy tắc sống còn: database là single source of truth.
Mọi dữ kiện thật, mọi con số, mọi ID, phải lôi từ DB ra. Đừng để agent tự nghĩ. Nó sẽ hallucinate ra transaction ID trông y như thật mà sai bét. Agent được phép suy luận về cách làm, nhưng dữ kiện phải có nguồn.
Đây là chỗ bộ ba tool-database-RAG phát huy tác dụng. Agent lên plan, nhưng mỗi lần lấy data phải qua tool query data thật. Không được phép improvise trên dữ kiện.
7. Phần Kinh Điển: Hiểu Khách Hàng
Phần cuối luôn là bài kinh điển của nghề làm phần mềm. Hiểu khách hàng. Và với agentic AI, đôi khi bạn phải hiểu hơn cả chính họ.
Lý do là mảng này quá mới. Khách nghe đồn agent làm được mọi thứ, nhưng chưa rõ mình thật sự cần gì. Thế là đưa ra yêu cầu trên trời:
“Tôi muốn nhập URL vào, agent tự truy cập, lấy hết thông tin, suy luận và tạo plan hoàn chỉnh.”
Nghe đơn giản. Nhưng thực ra đó là cả tool chain, effort dev cực lớn, độ ổn định hên xui. Trong khi ngồi đào sâu nhu cầu, hỏi kỹ họ dùng để làm gì — nhiều khi ý thật đơn giản hơn nhiều. Họ có sẵn file rule nội bộ, chỉ muốn agent đọc file đó khi làm việc. Xử lý gọn: đẩy file lên RAG, hoặc nhét vào system prompt, xong.
Hiểu đúng nhu cầu tiết kiệm cho khách cả tháng dev, và cứu chính bạn khỏi đống effort vô nghĩa. Kỹ năng này quan trọng ngang kỹ thuật, mà ít ai chịu rèn.
Tạm Kết
Agentic AI là làn sóng tuyển dụng mới, ai nhanh chân thì có lợi thế. Nhưng đào xuống tận gốc, nền tảng vẫn là cloud engineering. Bạn phải biết dựng infra rẻ, kiểm soát cost, vận hành đúng.
Mấy khóa “3 tháng thành chuyên gia AI” bán giấc mơ. Thực tế: AI agent là sản phẩm phần mềm có dùng LLM. Không biết làm phần mềm thì không làm được agent. AI là phần cherry trên cake, không phải cái cake.
Cái gì tách biệt demo khỏi production:
- Training đặc thù ngành, không phải prompt generic
- Hạ tầng khởi đầu rẻ, scale khi đã chứng minh
- Kiến trúc hub-and-spoke lớn theo sản phẩm
- Cost tagging từ ngày đầu
- Đào sâu nhu cầu khách trước khi viết dòng code đầu tiên
Agent ngày càng thông minh hơn. Nhưng engineering, kiến trúc, kỷ luật chi phí, và hiểu khách hàng — đó vẫn là kỹ năng con người. Và hiện tại, đó là cái nhà tuyển dụng thực sự tìm kiếm.
Bạn đang dựng agent trong production? Tôi muốn nghe pattern nào hiệu quả với team bạn. Tooling thay đổi nhanh — điều quan trọng là kỷ luật engineering bên dưới.
Tham Khảo & Nguồn
-
“The Reasoning Trap: How Enhancing LLM Reasoning Amplifies Tool Hallucination” — ICLR 2026, Rio de Janeiro. Training model reasoning mạnh hơn qua RL lại tăng tỉ lệ tool-hallucination. [AI News Digest, 29/04/2026]
-
Khảo sát OutSystems 2026 với IT Leaders — 96% doanh nghiệp chạy AI agent, nhưng 94% lo ngại agent sprawl tăng complexity và security risk. Chỉ 12% có nền tảng quản lý tập trung. [MachineLearningMastery]
-
Phân bố kiến trúc Agentic AI trong production — 66.4% hệ thống agentic AI production dùng pattern orchestrator-worker (hub-and-spoke). [DEV Community — Multi-Agent Systems]
-
Amazon S3 Vectors — Rẻ hơn tới 90% so với OpenSearch Serverless, tích hợp sẵn Bedrock Knowledge Bases, hiện có mặt tại 31 AWS regions. [AWS Storage Blog] | [Amazon S3 Vectors]
-
Hiệu suất S3 Vectors cho Agent Tool Selection — Vector search giảm chi phí LLM inference hơn 92% ($0.015 vs $0.202/query), đạt accuracy 82.3% vs baseline 75.8%, latency nhanh hơn 21%. [AWS Storage Blog]
-
Bedrock Agent Token Amplification — Một query người dùng có thể trigger gấp 4-8 lần token ước tính qua các bước suy nghĩ, tool call, và retry trung gian. [CloudZero — Amazon Bedrock Pricing]
-
AWS Bedrock Pricing & Application Inference Profiles — Phân bổ chi phí theo dự án qua inference profiles với Cost Explorer filter theo tag. [Bacancy Technology]
-
Bedrock AgentCore Pricing — 12 component tính phí độc lập theo 5 mô hình billing. Các chi phí bất ngờ thường gặp gồm idle session memory và CloudWatch observability. [Cloud Burn]
-
Prompt Caching cho Bedrock — TTL cache 1 giờ cho Claude Sonnet 4.5, Haiku 4.5, và Opus 4.5 (tháng 1/2026). Cache reads rẻ hơn ~90% so với input tokens thông thường. [Finout — AWS Bedrock Optimization]
-
Rủi ro Hallucination lan truyền trong Multi-Agent — Trong hệ thống multi-agent chia sẻ memory, một entry hallucinate duy nhất có thể lan tới mọi agent downstream. [The New Stack]
-
Chi phí phát triển AI Agent năm 2026 — Từ $8,000 cho PoC đơn giản tới $150,000+ cho hệ thống multi-agent production. Guardrails và monitoring chiếm 20-30% chi phí production build. [Unico Connect]
-
Kiến trúc Hub-and-Spoke cho AI Workflows — Cô lập spokes loại bỏ overhead phối hợp, shared state, và sự mơ hồ về ownership. [Medium — Nowshad Jawad]
-
Enterprise AI Agent Platforms 2026 — Zero-trust security, composable agent mesh, và dynamic peer selection đang nổi lên như alternative cho hub-and-spoke. [Mindra Blog]
-
Suy giảm hiệu suất hệ thống ML — 91% hệ thống ML bị suy giảm hiệu suất theo thời gian, cần giám sát liên tục. [Best Practices for AI Agent Implementations]
-
AI Hallucinations năm 2026 — Frontier models cải thiện factuality qua từng năm, nhưng khoảng cách giữa “trả lời câu hỏi” và “trả lời đúng” vẫn là vấn đề reliability trung tâm. [Maxim AI]