
If You’re About to Interview for an AI Role, Read This First
Agentic AI is the hottest hiring keyword in 2026. Every company wants their own agent. If you’re interviewing soon, there’s a good chance you’ll face questions about building and shipping AI agents in production.
This isn’t another hype article. This is a field report — from a team that’s been building and operating AI agents for enterprise clients, making mistakes, and slowly learning what actually works. I’m writing this so you can skip the expensive lessons I had to pay for.
1. “We Already Have ChatGPT and Claude — Why Build a Custom Agent?”
This is the question clients ask most. And it’s a fair question. From the outside, those chatbots seem to do everything.
They’re powerful. They’re smart. But they have two fundamental problems at enterprise scale.
First, cost. Calling frontier APIs continuously at enterprise volume produces invoices that make CFOs flinch. A single Bedrock Agent workflow can consume 4–8x the tokens you’d estimate from the user prompt and final response — every intermediate thinking step, every tool call, every retry burns tokens.
Second, domain specificity. General agents don’t understand your business rules.
Here’s a real example from one of our projects: a security operations agent for a CCoE (Cloud Center of Excellence) team at a large enterprise. Claude Opus and GPT-5 are brilliant at writing code — no argument there. But ask them to plan a penetration test following the company’s internal security standards, or to write a report in the exact format the CISO expects? They’re like a smart intern on day one — talented but clueless about the organization’s playbook.
The client needed an agent that could:
- Understand the organization’s internal security requirements
- Learn from past attack patterns to build future test plans
- Generate reports in the exact format with the exact insights leadership wants — not the generic summaries that general-purpose agents produce
And there was one more constraint — critical for large organizations: data sovereignty. They needed everything running on infrastructure where data never leaks back to train someone else’s model. Internal security data getting exfiltrated is a career-ending event. The solution: AWS Bedrock running Claude Sonnet 4.5 — balanced between cost and quality, with data staying inside their own account.

2. “But What About Hallucinations?”
Here’s the part that sounds paradoxical. LLMs are famous for making things up. How do you quality-control an agent built on a model that hallucinates?
The ICLR 2026 paper “The Reasoning Trap” actually made this worse — training models for stronger reasoning through reinforcement learning increases tool-hallucination rates. Better reasoning doesn’t mean better grounding.
But in practice, I’ve found that most hallucinations in agent systems come from exactly two situations:
- Insufficient input data — the agent doesn’t have enough information to answer, so it fills the gap with plausible-sounding fiction
- Context window overload — cramming too much into the context window until the model gets confused
If you build proper mechanisms for feeding data to your agent, you can control output quality. The solution is the tool-database-RAG triad: give the LLM a set of tools with clear instructions for when to use each one. The agent follows the tools instead of improvising.
Rule of thumb: The agent is allowed to reason about approach. But facts — every ID, every number, every data point — must come from the database. Never let the agent invent a transaction ID. It will look perfectly real and be completely wrong.
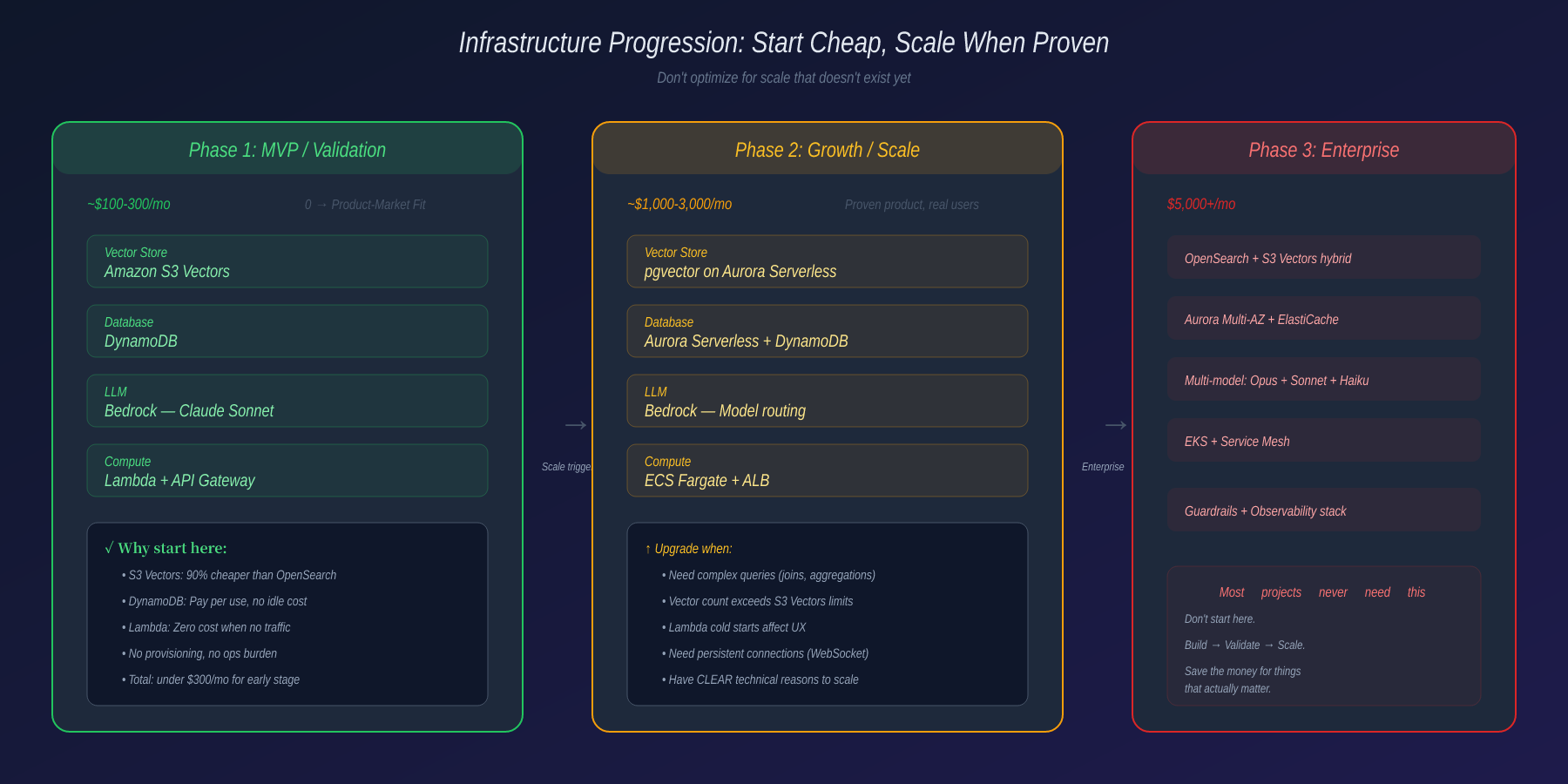
3. Infrastructure Design: Start Small or Burn Cash
Before talking about cost optimization, let me address a misconception I see constantly in people new to this space.
Building an AI agent is not just “calling some LLM APIs.” At its core, it’s still software engineering. You still need:
- Backend for business logic
- Frontend for users to interact with
- Database for storage
- And now, on top of all that, monthly LLM API bills
The old engineering fundamentals don’t disappear. Agentic AI is just another layer on top. Anyone who thinks learning “just AI” is enough to build production agents is in for a rude awakening. The AI part is often the easiest part. The hard part is integrating it into a system that actually runs without burning money.
The Infra Money Pit
This is where I’ve seen teams waste the most money, starting from day one.
When building RAG and vector storage for agents on AWS, don’t jump straight to pgvector or OpenSearch. They’re expensive, operationally heavy, and usually over-engineered for a product that hasn’t proven it can survive.
Use Amazon S3 Vectors instead. Launched in late 2025, it stores and queries vectors directly in S3 — up to 90% cheaper than OpenSearch Serverless, no provisioning needed, and natively integrated with Bedrock Knowledge Bases. For an early-stage agent with tens of millions of vectors, it’s more than enough. S3 Vectors also reduces LLM inference costs by over 92% through smarter tool selection — only sending relevant tools to the model instead of the entire catalog.
For metadata and chat history, try DynamoDB before reaching for RDS. It’s serverless, you pay per use, and at the early stage you don’t need complex joins. The cost savings are surprising.
My rule: Go to production, scale for real, and have clear technical reasons before upgrading to heavy infrastructure. Don’t optimize for a scale that doesn’t exist yet. Save that money for something useful.
4. Cost Management: The Bedrock Bill Trap
Bedrock models can’t be tagged by default. More precisely: when one AWS account runs multiple projects using the same model, the invoice shows cost per model, not per project. Your boss sees “Claude Sonnet: $X,000” but has no idea which project is eating the budget.
The Fix: Application Inference Profiles
Create a separate inference profile for each project. Attach cost allocation tags. Call the model via the profile’s ARN instead of the model ID directly. Then go to Cost Explorer and filter by tag — instant per-project billing visibility.
The elegant part: when a project upgrades models (Sonnet 4.5 → Opus, for example), billing still tracks to the project, not the model. No reset.
Other Cost Levers That Actually Work
| Strategy | Savings | When to Use |
|---|---|---|
| S3 Vectors instead of OpenSearch | ~90% on vector storage | New builds, < billions of vectors |
| Prompt caching (1hr TTL) | ~90% on cache reads | Stateful conversations |
| Model routing (cheap → frontier) | 40–60% blended cost | Mixed complexity workloads |
| Batch inference | 50% per token | Nightly reports, bulk classification |
| Context compression | Variable | Large RAG payloads |
5. Agent Architecture: Chat Is Where Teams Stumble
99% of agents have a chat function. And chat is where most teams break things. Sounds strange — what’s hard about chat? Let me explain.
An agent in a specific domain must talk like a real practitioner in that domain. A healthcare agent must converse like a doctor — asking the right symptoms, using the right terminology. A security agent must talk like a DevSecOps engineer — understanding attack contexts, testing procedures. The conversation flow for each domain is completely different. You can’t copy-paste a chat feature from one project to another and expect it to work.
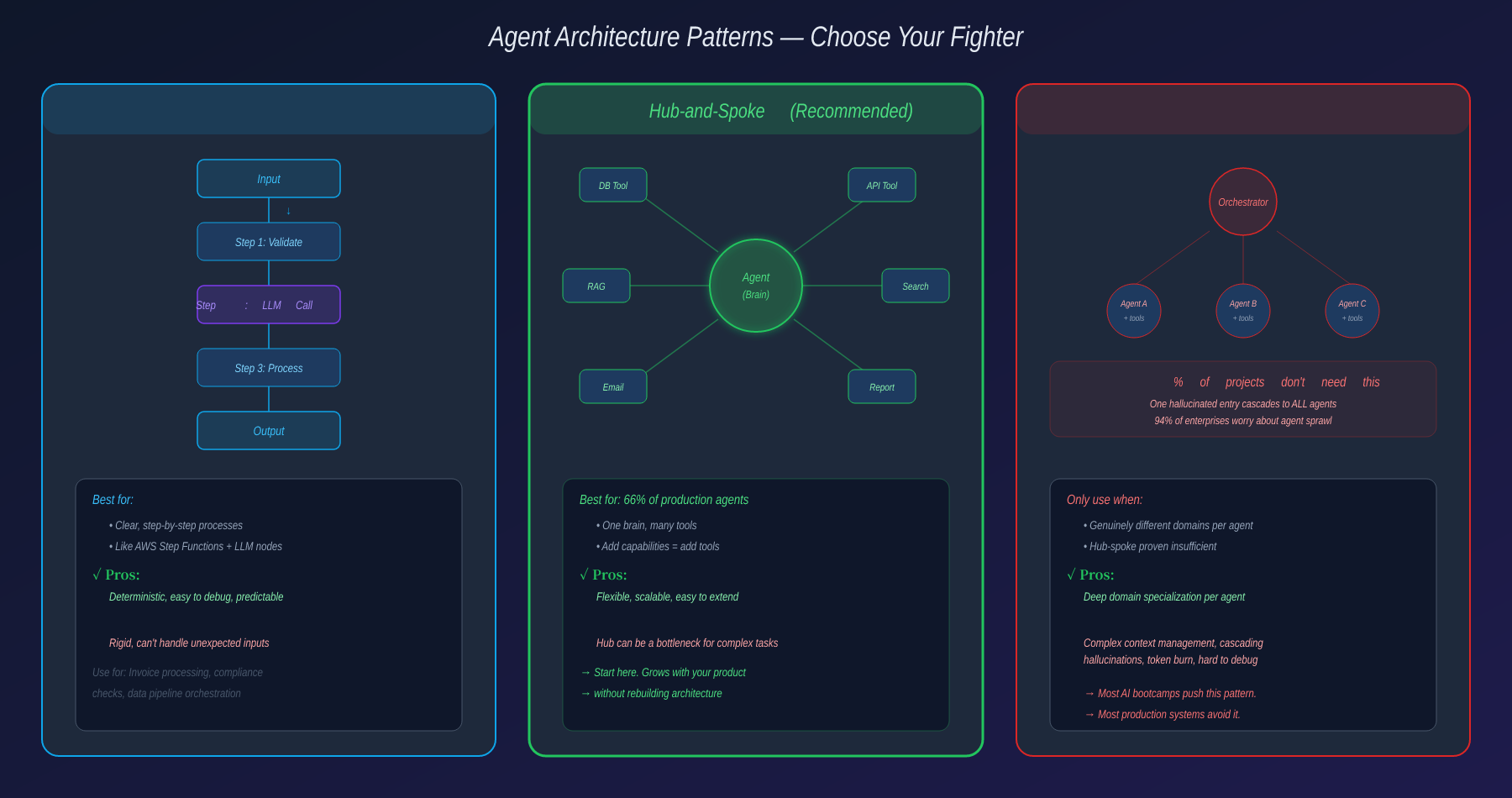
Three Architecture Patterns
You need to choose a design pattern from day one:
Workflow — Essentially coded pipelines (like AWS Step Functions) where some nodes call an LLM for reasoning. Deterministic, easy to debug, great for well-defined processes.
Hub-and-Spoke — One central agent with satellite tools. The agent reads the user’s request, then loops through tool calls to process and respond. One brain, many hands. 66.4% of production agentic AI systems use this pattern in 2026.
Multi-Agent — One or more orchestrator agents coordinating specialized child agents, each with their own tool sets for different domains.
The Multi-Agent Trap
The internet and AI models themselves love to suggest multi-agent architectures. I read those suggestions and cry-laugh.
Because 99% of projects don’t need more than one agent.
It’s not that multi-agent is bad. The problem is complexity. To make a multi-agent system work well, you need to control context and instructions with surgical precision. Too little context and agents can’t do their job. Too much and you burn tokens for nothing — and the bill counts every single one. Princeton researchers warned that in multi-agent systems sharing memory, a single hallucinated entry can cascade to every downstream agent.
OutSystems’ 2026 survey of nearly 1,900 IT leaders found that 96% of enterprises run AI agents — but 94% are concerned about sprawl increasing complexity, technical debt, and security risk. Only 12% have a central platform to manage them.
Hub-and-spoke is usually the right answer. No matter how complex the requirement, the agent just loops through tool calls. Want to add a capability? Code a new tool, update the catalog, done. The architecture grows with the product without requiring a rebuild.
6. Agents Must Plan — But Facts Come from the Database
For complex requests, an agent needs planning capability. When a user says “do A, then B, then C,” the agent must build an execution plan — understanding dependencies, sequencing, and prerequisites.
But here’s the survival rule: use the database as the single source of truth.
Every real fact, every number, every ID must come from the database. Don’t let the agent think up data. It will hallucinate transaction IDs that look perfectly real and are completely fabricated. The agent can reason about how to do something, but the what — the actual data — must have a verifiable source.
This is where the tool-database-RAG triad pays off. The agent plans the approach, but every data retrieval goes through a tool that queries real data. No improvisation on facts.
7. The Classic: Understanding Your Client
The final section is the eternal lesson of software engineering. Understand your client. And with agentic AI, sometimes you need to understand them better than they understand themselves.
The reason is that this field is still new. Clients hear that agents can do everything, but they don’t actually know what they need. So they come with sky-high requirements:
“I want to input a URL, and the agent automatically accesses it, extracts all relevant information, reasons about it, and produces a complete plan.”
Sounds simple. But that’s actually an entire tool chain, massive dev effort, and questionable reliability. Meanwhile, if you dig deeper into their actual need, it’s often much simpler. They have an internal rules file and just want the agent to reference it when working. That’s a straightforward solve — push the file to RAG, or embed it directly in the system prompt.
Understanding the real need saves your client months of development cost and saves you from a mountain of pointless effort. This skill — requirement excavation — is as important as any technical skill, yet few people invest in developing it.
The Bottom Line
Agentic AI is the new hiring wave, and early movers have an advantage. But dig beneath the surface, and the foundation is still cloud engineering. You need to know how to build infrastructure cheaply, control costs, and operate systems properly.
The “3-month AI expert” courses sell a fantasy. The reality is: AI agents are software products that happen to use LLMs. If you can’t build software, you can’t build agents. The AI is the cherry on top, not the cake.
What separates a demo from production:
- Domain-specific training, not generic prompts
- Infrastructure that starts cheap and scales when proven
- Hub-and-spoke architecture that grows with the product
- Cost tagging from day one
- Client needs excavation before writing a single line of code
The agents are getting smarter every quarter. But the engineering, the architecture, the cost discipline, and the client understanding — those are still human skills. And right now, they’re what hiring managers are really looking for.
Building agents in production? I’d love to hear what patterns work for your team. The tooling changes fast — what matters is the engineering discipline underneath.
References & Sources
-
“The Reasoning Trap: How Enhancing LLM Reasoning Amplifies Tool Hallucination” — ICLR 2026, Rio de Janeiro. Training models for stronger reasoning through RL increases tool-hallucination rates. [AI News Digest, April 29, 2026]
-
OutSystems 2026 IT Leaders Survey — 96% of enterprises run AI agents, but 94% are concerned about sprawl increasing complexity and security risk. Only 12% have a central management platform. [MachineLearningMastery]
-
Agentic AI Market Architecture Distribution — 66.4% of production agentic AI systems use the orchestrator-worker (hub-and-spoke) pattern. [DEV Community — Multi-Agent Systems]
-
Amazon S3 Vectors — Up to 90% cheaper than OpenSearch Serverless, natively integrated with Bedrock Knowledge Bases, now available in 31 AWS regions. [AWS Storage Blog] | [Amazon S3 Vectors]
-
S3 Vectors Performance for Agent Tool Selection — Vector search reduces LLM inference costs by over 92% ($0.015 vs $0.202 per query), achieves 82.3% accuracy vs 75.8% baseline, with 21% faster latency. [AWS Storage Blog]
-
Bedrock Agent Token Amplification — A single user query can trigger 4–8x the estimated tokens through intermediate thinking, tool calls, and retries. [CloudZero — Amazon Bedrock Pricing]
-
AWS Bedrock Pricing & Application Inference Profiles — Per-project cost allocation via inference profiles with tag-based Cost Explorer filtering. [Bacancy Technology]
-
Bedrock AgentCore Pricing — 12 independently billable components across 5 billing patterns. Common surprises include idle session memory and CloudWatch observability charges. [Cloud Burn]
-
Prompt Caching for Bedrock — 1-hour cache TTL for Claude Sonnet 4.5, Haiku 4.5, and Opus 4.5 (January 2026). Cache reads cost ~90% less than standard input tokens. [Finout — AWS Bedrock Optimization]
-
Multi-Agent Cascading Hallucination Risk — In multi-agent systems sharing memory, a single hallucinated entry can spread to every downstream agent. [The New Stack]
-
AI Agent Development Cost in 2026 — Ranges from $8,000 for a simple PoC to $150,000+ for production multi-agent systems. Guardrails and monitoring account for 20–30% of production build cost. [Unico Connect]
-
Hub-and-Spoke Architecture for Reliable AI Workflows — Deliberate isolation of spokes eliminates coordination overhead, shared state concerns, and ownership ambiguity. [Medium — Nowshad Jawad]
-
Enterprise AI Agent Platforms in 2026 — Zero-trust security, composable agent mesh architecture, and dynamic peer selection emerging as alternatives to hub-and-spoke. [Mindra Blog]
-
ML System Performance Degradation — 91% of ML systems experience performance degradation over time, requiring continuous monitoring. [Best Practices for AI Agent Implementations]
-
AI Hallucinations in 2026 — Frontier models show measurable improvement on factuality benchmarks year-over-year, but the gap between “answers a question” and “answers correctly” remains the central reliability problem. [Maxim AI]